ГЛАВА 15. ЯЗЫК АССЕМБЛЕРА БОЛЕЕ ПОДРОБНО
15.1. ВВЕДЕНИЕ
При изучении языка ассемблера проявляется соотношение между программами и данными, которое часто бывает скрыто в языках высокого уровня. Как было показано в предыдущих главах, инструкции (программа) и данные используют одну и ту же память ЭВМ. На самом деле это справедливо не только для ЭВМ семейства VAX, но также и для большинства ЭВМ универсального назначения, как для больших, так и для малых[1].
По сути это означает, что между программами и данными имеется весьма незначительное различие. В данной главе будут продемонстрированы расхождения такого рода, кроме того, будет показано, как программы, написанные пользователями, обрабатываются различными компонентами операционной системы. В действительности программу можно рассматривать как данные, которые считываются какой-либо обрабатывающей программой. Такие обрабатывающие программы упоминались в предыдущих главах, но подробно не разбирались - это будет сделано в данной главе. В дополнение будут рассмотрены некоторые вопросы, связанные с созданием программ, такие как написание позиционно независимого кода.
15.2. ФОРМАТ ПРОГРАММЫ
ОСНОВНЫЕ ВИДОИЗМЕНЕНИЯ ПРОГРАММЫ
Прежде чем программы, написанные на языке ассемблера или языке Фортран, могут быть выполнены, они обычно проходят различные стадии преобразования. На каждой стадии программа воспринимается как данные некоторого определённого вида. Далее будут рассмотрены форматы этих данных и их структура, а также различные обрабатывающие программы, используемые на каждой стадии преобразования.
На ЭВМ семейства VAX программы, написанные на языке ассемблера, и большинство программ на языках высокого уровня могут находиться в следующем виде:
- Исходный текст. Исходный текст программы состоит из символьных строк, образующих операторы языка программирования.
- Объектный код. Представляет собой оттранслированную программу, операторы которой конвертированы в двоичный машинный код ЭВМ VAX. Однако не все адреса в программе транслируются в двоичный код. Это происходит потому, что ассемблер (или компилятор) не определил значения для глобальных имён, а также потому, что может понадобиться настройка адресов программы. Вследствие этого для компоновщика должна быть обеспечена соответствующая информация, на основе которой он мог бы завершить преобразование программы.
- Файл выполняемого образа. Компоновщик берёт один или несколько объектных файлов и перемещает программные модули, производя настройку адресов так, чтобы каждый из них занимал свою отдельную область памяти. Глобальным именам присваиваются двоичные значения. В результате образуется файл выполняемого образа, содержащий двоичный код, который может быть загружен в память часто без какой-либо дальнейшей модификации.
- Активизированная программа. Представляет собой готовую к выполнению программу, помещённую в определённую область памяти ЭВМ. Отличие между активизированной программой и файлом выполняемого образа состоит в том, что активизированной программе назначается область выполнения в виртуальной памяти, тогда как файл выполняемого образа просто хранится на некотором внешнем запоминающем устройстве большой ёмкости. В операционной системе VAX/VMS имеется программа, называемая активатором образа, которая назначает программе, находящейся в файле выполняемого образа, пространство в виртуальной памяти. То, как это делается, тесно связано с работой виртуальной памяти и описывается более подробно в разделе, посвящённом загрузке в виртуальную память.
ИСХОДНЫЙ ТЕКСТ ПРОГРАММЫ
На ЭВМ семейства VAX исходный текст (или код) программы состоит из строк символов в коде ASCII, имеющих произвольную длину. Эти символьные строки разбиваются на части, называемые операторами, или строками текста, или записями. Точный формат строки исходного текста программы зависит от конкретного языка программирования, такого как язык ассемблера, Паскаль или Фортран. В структуре записей файла каждая строка отделяется от других с помощью управляющей информации. Длина строки текста обычно ограничивается сверху некоторым фиксированным числом символов, например 80 символами.
Имеется целый ряд обрабатывающих программ, предназначенных для работы с исходным текстом. Обрабатывающие программы - это программы, воспринимающие исходный текст как данные, т.е. как некоторую строку символов, чтобы выполнить над ней некоторые операции. Одни программы выполняют относительно простые операции, как, например, программ, осуществляющая копирование файла из одного каталога в другой. Эта программа вызывается по команде COPY (см. приложение Г). Другие программы, такие как редакторы текста (см. приложение Д) или ассемблер, выполняют специфические непосредственно над самим исходным текстом.
РЕДАКТИРОВАНИЕ ИСХОДНОГО ТЕКСТА
Редакторы текста, такие как EDT и TECO, в основном используются для создания, модификации исходного текста, а также для внесения в него добавлений. Однако применение редакторов текста не ограничивается каким-либо конкретным языком программирования; они могут работать с любым текстом в коде ASCII, имеющим строчно-ориентированную структуру, включая текст, совершенно не связанный с программированием, например литературный. Редакторы текста распознают разделители записи и страницы как служебные символы, но оставшиеся символы в записи обрабатываются, как обычные данные. Редакторы текста работают следующим образом: копируют или весь текст целиком, или большой блок текста в память как один большой массив символов. (Большой текстовый файл может не поместиться в выделенной памяти и должен быть разбит на страницы, каждая из которых редактируется отдельно. Некоторые редакторы текста, подобные редактору EDT, позволяют перемещаться со страницы на страницу как в прямом, так и в обратном направлении. Другие, подобно редактору TECO, обеспечивают перемещение по страницам строго в одном направлении - вперёд.) Разнообразные команды редактирования дают редактору указание обнаружить определённое место в массиве символов и вставить или удалить символы из массива. Вставка и удаление часто бывают медленными, так как вся оставшаяся до конца массива часть может целиком перекопироваться, чтобы освободить или занять пустое пространство. Тем не менее, так как ЭВМ семейства VAX имеют достаточное быстродействие, пользователь обычно не замечает каких-либо задержек по времени, если только вставки и удаления не повторяются. После завершения редактирования содержимое памяти копируется обратно в файл, расположенный на внешнем запоминающем устройстве.
ПРОЦЕСС АССЕМБЛИРОВАНИЯ
Читатель уже немного знаком с процессом ассемблирования, поскольку он рассматривался в различных главах книги, начиная с гл. 4. Однако если взглянуть на этот процесс с точки зрения обработки данных, то прояснятся некоторые детали. Как и большинство обрабатывающих программ, ассемблер считывает данные из входного файла и записывает их в выходные файлы[2]. В простейшем случае имеется один входной файл, в котором содержится исходный текст программы. Имеется два выходных файла: первый, в который помещается оттранслированная программа в двоичном формате, называется объектным файлом; во второй файл выводится листинг программы. Подобная информация выводится в оба файла, но есть некоторые различия. В то же время формат этой информации полностью различается, что будет показано в следующем разделе.
Как было сказано выше, на ЭВМ VAX процесс ассемблирования является двухпроходным. Это значит, что входной файл должен быть полностью считан ассемблером дважды, так как ассемблер не может назначить адреса ячейкам, которые определяются позже в программе. Это известно как ссылки вперёд, такие ссылки могут появиться в ситуациях, аналогичных ситуации, показанной на рис. 15.1. Ссылка на имя NEXT содержится в инструкции JSB. Однако для этой инструкции не может быть сгенерирован код, так как ассемблер ещё не считал строку программы, в которой определяется имя NEXT. Хотя в этом примере может показаться, что ассемблеру для разрешения ссылки вперёд надо просмотреть текст программы лишь не намного вперёд, следует запомнить: ссылки вперёд часто могут быть в большой программе найдены только через много страниц.
JSB NEXT . . . NEXT:
Рис. 15.1. Ссылка вперёд
Решением, принятым на ЭВМ VAX, является просмотр программы целиком, выполняемый один раз. Во время первого прохода ассемблера создаётся таблица имён. На втором проходе имена заменяются числами, чтобы сгенерировать машинный код программы. Замечательным является то, что в ассемблере ЭВМ VAX процессы обработки, выполняемые на первом и втором проходе, почти идентичны. Основное различие состоит в том, что во время первого прохода вывод информации подавляется. Если бы генерация машинного кода осуществлялась на первом проходе, то для каждой ссылки вперёд могли бы появляться сообщения об ошибке, вызванные появлением неопределённого имени.
Во время второго прохода повторяется аналогичная обработка. Но теперь уже существует полная таблица имён, созданная на первом проходе. Таблица имён будет содержать значения всех разрешённых ссылок вперёд. Во время второго прохода могут быть образованы объектный файл и файл листинга, так как каких-либо неопределённых имён больше не будет, если только программист сам не оставил их неопределёнными.
Следует заметить, что использование на ЭВМ VAX двухпроходного ассемблера не является единственным решением проблемы ссылок вперёд. Имеются и другие решения. Одно из них - умышленное избежание ссылок вперёд программистом. Большинству пользователей такое решение не нравится. Другое решение состоит в том, что генерация кода осуществляется на первом проходе, а обнаруженные ссылки вперёд помечаются. Затем, когда ссылки вперёд будут разрешены, объектный файл будет скорректирован в соответствии с отмеченными ссылками. Такой ассемблер иногда называется полуторапроходным. Есть и ещё решение - оставить разрешение ссылок вперёд другой программе, компоновщику, загрузчику или непосредственно самому процессору ЭВМ с помощью некоторой схемы косвенной адресации.
ДАННЫЕ ДЛЯ АССЕМБЛЕРА
Как уже упоминалось, входные и выходные файлы ассемблера на самом деле представляют собой входные и выходные данные для программы. Два из трёх файлов данных, а именно файл с исходным текстом программы и файл листинга, предназначены для пользователей. Поэтому эти файлы являются символьными, а их содержимое может быть распечатано постранично, как обычный текст. Читатель уже должен быть знаком с тем, как выглядит содержимое этих файлов. Но человек воспринимает информацию, содержащуюся в этих файлах, совсем не так, как ЭВМ. Слова, строки, страницы воспринимаются человеком как целое. Восприятие ЭВМ намного более ограничено; таким образом, символьные данные должны обрабатываться программой символ за символом или в лучшем случае небольшими группами символов (вероятно, до восьми символов одновременно при выполнении на ЭВМ VAX операций над квадрасловами).
По мере того как ассемблер считывает информацию из файла с исходным текстом программы, он должен быть способен различать в строке поля. Такими полями являются поле метки, поле кода операции, поле операндов и комментарии. Есть два распространённых способа распознавания полей. Первый основан на использовании полей фиксированной длины, начинающихся с определённых позиций символов на строке. Например, операторы Фортрана занимают на строке позиции (колонки) с 7-й по 72-ю. По сути это правило применяется в Фортране вследствие того, что первоначально язык был реализован на вычислительных системах, в которых использовался ввод и вывод с перфокарт. Аналогично первые ассемблеры для ЭВМ фирмы IBM были ориентированы на обработку полей, имеющих фиксированное расположение.
Второй способ распознавания полей основывается на использовании разделителей - знаков пунктуации, таких как двоеточие, точка с запятой, запятые, пробелы и т.д., как это делается в языке ассемблера для ЭВМ VAX. Для большинства современных приложений данный способ является более подходящим, поскольку ввод осуществляется с терминала, где позицию символа определить труднее, чем на перфокарте. Как следствие, многие ассемблеры используют комбинацию из отдельных фиксированных полей и разделителей. Например, в ассемблере для ЭВМ CDC COMPAS требуется, чтобы метки начинались с колонки 1, а коды операций начинались с любой колонки, кроме первой. Следовательно, чтобы отличать метки от кодов операций и операндов, не требуется двоеточие.
Теперь можно приблизительно описать функции, выполняемые различными частями ассемблера для ЭВМ VAX на первом и втором проходе. На каждом цикле своей работы ассемблер осуществляет выборку строки исходного текста и анализирует её символ за символом[3]. Начальные пробелы в строке игнорируются[4]. Предполагается, что первый отличный от пробела символ является началом имени. Ассемблер накапливает последовательно поступающие символы до тех пор, пока не будет обнаружен знак пунктуации. Обычно это пробел, двоеточие или знак равенства.
Если первый отличный от пробела символ является двоеточием, это означает, что накопленные символы представляют собой метку, и в таблице имён подаётся соответствующая запись. Если первый отличный от пробела символ - знак равенства, то ассемблер предполагает, что далее следует выражение, которое должно быть вычислено, а его значение занесено в таблицу имён. Если это какой-нибудь другой символ, ассемблер считает, что накопленные символы являются кодом операции, директивой ассемблера или именем макроинструкции. Коды операций и директивы ассемблера группируются по классам. Например, инструкции ADDL2, MOVL и SUBL2 подобны так же, как между собой подобны инструкции BRB, BEQL и BNEQ. Для обработки кодов операций каждого класса есть специальные обрабатывающие подпрограммы, которые в соответствии с кодом операции обрабатывают поле операндов и генерируют объектный код. Строка исходного текста завершается или символом признака конца строки, или точкой с запятой. Комментарии, признаком начала которых является точка с запятой, ассемблером игнорируются.
Если выполняется второй проход, то генерируемый объектный код (если он есть) записывается в объектный файл и образуется строка листинга программы. В строку листинга программы заносятся шестнадцатеричные значения, представляющие объектный код, и адреса (переместимые (настраиваемые) адреса помечаются специальной отметкой), затем следуют номер строки и исходный текст в том виде, в каком он был во введённой строке исходного текста программы. Этот полный цикл повторяется и в конце концов завершается при обработке директивы .END.
РАСШИРЕНИЕ МАКРОИНСТРУКЦИЙ
Макропроцессор фактически представляет собой отдельную обрабатывающую программу, являющуюся на самом деле расширением языка ассемблера. Как было описано в гл. 10, макрообработка складывается из двух частей: определения макроинструкций и вызова или расширения макроинструкций. Когда встречается макроопределение, строки, расположенные между директивой .MACRO и соответствующей ей директивой .ENDM, копируются в область макроопределений.
При вызове макроинструкции её имя помещается в поле кода операции вводимой строки. При обнаружении макровызова начинает работать подпрограмма обработки макрорасширений. Эта подпрограмма копирует строки исходного текста, находящиеся в области макроопределений, в область расширения. Во время копирования замещаемые параметры заменяются аргументами, указанными в макровызове. В большинстве случаев осуществляется замена одной строки символов на другую без интерпретации.
После завершения расширения управление передаётся подпрограмме, отвечающей за выполнение проходов ассемблирования. При наличии макровызовов процесс ассемблирования несколько отличается от обычного. Если в области макрорасширения имеется какой-либо исходный код, то выборка строк программы осуществляется из этой области, а не из файла с исходным текстом программы. В остальном процесс ассемблирования осуществляется так же, как и раньше. Выборка строк из области макрорасширения будет продолжаться до тех пор, пока не будут выбраны все строки из этой области, после чего строки снова будут браться из файла с исходным текстом. Такое действие одинаково для двух проходов.
Если одна из строк в макрорасширении является макровызовом, происходит такой же процесс расширения, за одним исключением: расширенная макроинструкция всегда добавляется перед тем, что может оставаться в области расширения. Это позволяет из макроинструкций вызывать макроинструкции, внутри которых вызываются другие макроинструкции, и т.д. На вложенные вызовы макроинструкций нет никаких ограничений, кроме ограничения по памяти, накладываемого на область расширения. Поскольку область макрорасширений устроена как стек, макроинструкции могут быть даже рекурсивными и вызывать самих себя. Заметим, что в рекурсивных макроинструкциях вызов макроинструкции самой себя должен находиться в блоке условия, так чтобы процесс в конечном итоге был завершён.
УПРАЖНЕНИЯ 15.1
- Напишите программу, которая распечатывает по байтам содержимое всех своих
ячеек (как инструкции, так и данные). Она должна распечатывать также содержимое
16 регистров общего назначения. Содержимое ячеек и регистров распечатывается
в шестнадцатеричном и двоичном представлении. Например, распечатка может
иметь следующий вид:
Адрес
Шестнадцатеричное представление
Двоичное представление
00000200
AF
10101111
00000201
D0
10110000
. . .
. . .
. . .
- а) определите, какие части вашей программы (если они есть) представляют только инструкции, только данные или инструкции и данные? Почему?
- б) имеются ли в вашей распечатке какие-либо странности, например несовпадение шестнадцатеричных и двоичных значений? Почему? Можно ли это исправить?
- Напишите простую программу-редактор, которая работала бы подобно встроенному
редактору для языка Бейсик. Пусть:
- а) каждой строке предшествует шестизначный десятичный номер;
- б) ввод строчек может осуществляться в любом порядке, но распечатываться строки будут в порядке увеличения их номеров;
- в) если номер вводимой строки совпадает с номером записанной ранее строки, то прежняя строка будет удалена.
- г) строка с номером 999999 используется для завершения ввода и распечатки отредактированных данных. Например, при вводе строк:
000100
ПЕРВАЯ СТРОКА
000070
ВТОРАЯ СТРОКА
000120
ТРЕТЬЯ СТРОКА
000130
ЧЕТВЁРТАЯ СТРОКА
000120
ПЯТАЯ СТРОКА
999999
будет распечатано следующее
000070
ВТОРАЯ СТРОКА
000100
ПЕРВАЯ СТРОКА
000120
ПЯТАЯ СТРОКА
000130
ЧЕТВЁРТАЯ СТРОКА
- Приведённые ниже инструкции имеют различную структуру операндов и могли
бы быть отнесены к различным группам:
CLRL
ADDL2
BRB
JMP
CALLS
RET
MOVAB
ACBL
- а) в наиболее общем виде опишите операнды каждой инструкции;
- б) опишите, что бы делал ассемблер при обработке операндов этих инструкций.
- Опишите, для чего предназначены приведённые ниже директивы ассемблера?
Какие действия могут быть выполнены на каждом проходе ассемблирования при
обработке этих директив?
.LIST
.WORD
.REPT
.ASCII
- Вручную проделайте по шагам ассемблирование следующей программы; при
обработке каждой строки покажите, что будет находиться в области макроопределений
и в области макрорасширений:
.MACRO FAC A,N .IF EQUAL,N A=1 .IF_FALSE FAC A,N-1 A=A*N .ENDC .ENDM FAC NUM,3 .END
15.3. ОБЪЕКТНЫЙ КОД
ДВОИЧНЫЕ ФАЙЛЫ И СТРУКТУРА ЗАПИСЕЙ
Поскольку исходный текст программ и листинги предназначены для человека, то они записываются в файлы в символьном виде - в коде ASCII. Однако объектный код обычно не просматривается человеком, он считывается ЭВМ во время компоновки. Поэтому лучше использовать формат данных, наиболее подходящий для ЭВМ (лучше, чем код ASCII). Информация в символьных файлах представлена в некомпактном виде, так как обычно включает пробелы, знаки табуляции и другие знаки пунктуации, чтобы сделать данные удобными для чтения. Например, 16-битовое двоичное число может быть записано как четырёхзначное шестнадцатеричное число, отделённое одним пробелом от последующих чисел. Для такого представления потребовалось бы пять символов в коде ASCII или пять байтов данных. Тем не менее во внутреннем представлении 16-битовое число занимает только два байта. Следовательно, данные получаются намного более компактными и могут передаваться намного эффективнее, если они сохраняют внутреннюю двоичную форму представления. Файлы, содержащие информацию в таком виде, называются двоичными файлами.
Обычно большое число данных (или потенциально большое), которое хранится в двоичных файлах, требуется разбить на небольшие порции так же, как информация в символьных файлах разбивается на строки. Как было показано в гл. 11, эти порции данных называются записями. В основном имеется два способа сегментации двоичных файлов: записи фиксированной и записи переменной длины. В случае записей фиксированной длины существует соглашение, что все без исключения записи имеют некоторый фиксированный размер. Следовательно, не требуется иметь какую-либо управляющую информацию для описания длины каждой записи.
В объектных файлах, как будет показано далее, необходимо хранить данные различного вида и объёма. В этом случае записи переменной длины позволяют уменьшать занимаемое пространство памяти. Существует два основных способа для определения размера записей переменной длины. Эти способы аналогичны способам, применяемым в языках высокого уровня для разделения символьных строк. Например, первый способ основан на использовании указателя длины записи, который включается в запись как часть данных. Это подобно записи холлеритовских констант в Фортране. Например:
17HHERE'S A MESSAGE.
Символы 17Н в начале строки определяют длину сообщения, которое может содержать любые символы.
Другой способ определения длины записи основывается на применении управляющих символов, таких как "Возврат каретки" и "Перевод строки", используемых при вводе текста в коде ASCII с терминала. Но в этом случае становится неудобно работать с текстом, внутри которого также содержатся управляющие символы. Эта проблема весьма существенна для двоичных файлов, в которых любая комбинация битов может являться правильной информацией. Одно решение проблемы состоит в том, чтобы использовать дублирующий управляющий символ для указания одиночного управляющего символа в тексте. Такое решение применяется в Фортране, когда желательно заключить в кавычки строку, внутри которой тоже есть кавычки. Предыдущий пример может быть переписан следующим образом:
'HERE''S A MESSAGE.'
Две стоящие рядом кавычки обрабатываются, как одна кавычка в тексте. Этот способ может быть приспособлен для работы с двоичными данными; он применяется в некоторых стандартных протоколах передачи данных, таких как BISYNC (протокол, применяемый ЭВМ фирмы IBM, а также другими ЭВМ в вычислительных сетях). Тем не менее в операционной системе VAX/VMS для разграничения записей переменной длины применяются указатели длины записи, что будет рассмотрено в следующем разделе.
ВНУТРЕННИЙ ФОРМАТ ЗАПИСЕЙ НА ЭВМ VAX
Как было описано в гл. 11, на ЭВМ VAX информация в файлах разбивается на записи, к которым может быть осуществлён последовательный или прямой доступ. Записи могут иметь переменную или фиксированную длину. Для записей фиксированной длины не требуется разграничивать их начало или конец, так как размер записей известен и фиксирован. Но для записей переменной длины должен быть способ определения местонахождения их границ.
Большинство внешних запоминающих устройств большой ёмкости на ЭВМ VAX устроены так, что информация записывается в физические блоки длиной 512 байтов[5]. Для того чтобы установить формат записи и методы доступа для файла, в начале каждого файла записывается дополнительный блок. Обычно пользователь "не видит" этот блок, так как он содержит только управляющую информацию. Среди прочего этот блок содержит битовые коды, идентифицирующие тип записи и метод доступа, который используется для оставшейся части файла. Если вы любознательны, то можете посмотреть, что находится в данном блоке, с помощью команды DUMP/HEADER или DUMP/HEADER/NOFORMATED, введя их с терминала или поместив в задание, выполняемое в режиме пакетной обработки.
Остальные блоки файла содержат информацию пользователя, отформатированную так, как это указано в управляющем блоке. Если заданы записи переменной длины, что является обычным, то каждой записи предшествует 16-битовый указатель длины записи. Кроме того, при необходимости, для того чтобы число байтов в записи было всегда чётным, к концу записи добавляется нулевой байт. Таким образом, приведённые строки текста
Hello This is Some text . . .
могут иметь следующую структуру записей:
69 29 73 69 68 54 00 07 00 6F 6С 6С 65 48 00 05 ... 00 74 78 45 74 20 65 6D 6F 53 00 09 00 73
Отметим, что записи расположены здесь справа налево, так же как принято на ЭВМ VAX для дампов и листингов ассемблера. Вследствие того что каждая строка текста занимает в записи нечётное число байтов, к концу записи требовалось добавить нулевой байт 00.
Байты записи не обязательно должны содержать коды ASCII, они могут содержать любую комбинацию битов, поскольку указатели длины записей явно задают длину каждой записи. В некоторых других операционных системах, подобных системам для ЭВМ семейства PDP-11 фирмы DEC, для разграничения записей используются такие управляющие символы, как "Возврат каретки" (^X0D) или "Перевод строки" (^X0A). Это означает, что в середине записи эти символы не могут присутствовать в тексте. В таких операционных системах файлы часто разделяют на символьные и двоичные файлы. Как было описано выше, для разграничения записей в символьных файлах применяются управляющие символы, а в двоичных файлах используются указатели длины записей. В ОС VAX/VMS указатели длины записей применяются как для двоичных, так и для символьных файлов, тем самым минимизируется различие между ними. По сути различие заключается в том, что обычно символьные файлы имеют в управляющем блоке параметры, задающие управление кареткой. Первоначально такая информация указывается при создании файла в блоке доступа к файлу (см. гл. 11).
ОБЪЕКТНЫЙ МОДУЛЬ
Объектный модуль представляет собой форматированный двоичный файл, создаваемый ассемблером во время ассемблирования. Объектный модуль содержит весь двоичный машинный код, сгенерированный ассемблером. Тем не менее требуется ещё дополнительная информация. Вспомним, что программы на языке ассемблера обычно ассемблируются так, что они могут загружаться в различные области памяти, а несколько модулей программ и подпрограмм могут быть скомпонованы вместе.
Поэтому на ЭВМ VAX объектные модули обычно состоят из трёх секций. Первая секция содержит общую информацию о программе и используемых в ней глобальных именах; вторая секция - полученный после трансляции машинный код; в третьей секции содержится информация о том, как должен быть модифицирован машинный код при настройке программы на какую-либо область памяти и где в коде при настройке должны задаваться глобальные адреса или параметры. Эти три секции называются словарём глобальных имён, текстом и таблицей настройки.
Словарь глобальных имён. Состоит из одной или нескольких записей[6]. Записи состоят из полей, в которых указывается следующая информация:
- 1) длина программы и длина каждой программной секции, определённой директивой .PSECT;
- 2) относительное местонахождение для всех определённых в программной секции глобальных имён;
- 3) имена всех используемых в программе неопределённых глобальных имён;
- 4) прочая информация, такая как имя программной секции, заданное в директиве .TITLE.
Текст. Полученный после трансляции двоичный код называется текстом, текст состоит из ряда записей. Каждая запись, называемая блоком текста, содержит относительный адрес области памяти, куда должен быть загружен текст, а также некоторый машинный код.
Таблица настройки. За каждым блоком текста может следовать запись, содержащая закодированные указания для модификации предшествующего ей блока текста. Ниже приведены примеры различных указаний, которые можно найти в таблице настройки:
- Модифицировать в предшествующем блоке текста заданный адрес, складывая его с действительным адресом начала программы. Вспомним, что ассемблер, как правило, присваивает программной секции начальный адрес ^X00000000, который обычно модифицируется при загрузке программы.
- Заменить заданный адрес в блоке текста смещением, вычисленным относительно значения в программном счётчике во время выполнения инструкции.
- Заменить адрес назначенным глобальному имени абсолютным адресом.
Существуют и другие указания по настройке, аналогичные перечисленным выше, но здесь они рассматриваться не будут. Отметим, что в некоторых инструкциях должна осуществляться модификация либо байта, либо слова, либо длинного слова.
Все двоичные записи в объектном модуле содержат коды, определяющие тип записи. Кроме того, имеются коды, отмечающие как концы различных секций модуля, так и конец самого модуля. Это позволяет объединять несколько модулей вместе, помещая их в один файл. Если при трансляции указывался ключ /DEBUG, то к объектному модулю будут добавлены дополнительные секции. Эти секции необходимы для сохранения таблицы имён и другой информации для отладчика.
ПРОЦЕСС КОМПОНОВКИ
Компоновка нескольких объектных модулей в одну абсолютную программу в машинном коде является двухпроходным процессом. Два прохода необходимы по тем же соображениям, что и два прохода при ассемблировании. Глобальные имена могут использоваться в одном модуле, но их определение может находиться в другом модуле, расположенном далее.
Во время первого прохода компоновки производятся распределение пространства памяти и определение значений для глобальных имён. Необходимая для этого информация содержится в словарях глобальных имён модулей. Компоновщик по мере считывания словарей глобальных имён может выделять пространство в памяти ЭВМ исходя из информации о длине каждой программной секции. Затем программным секциям могут быть назначены их истинные, а глобальным именам - абсолютные адреса. После чего становится возможным провести модификацию, указанную в таблицах настройки.
Таким образом, во время второго прохода блокам текста назначаются абсолютные адреса вместо относительных. Отдельные адреса модифицируются в соответствии с тем, что указано в таблицах настройки. В результате будет получена программа в абсолютных адресах, которая может быть непосредственно загружена в указанную область виртуальной памяти ЭВМ VAX и выполнена без какой-либо дальнейшей модификации, поскольку она содержит всю необходимую для выполнения информацию; выполнение программы начинается с адреса ^X200. В других случаях выходная информация компоновщика должна быть в той или иной степени модифицирована.
ПРОГРАММНЫЕ СЕКЦИИ
Программные секции представляют собой блоки кода в программе, используемые для некоторого специального назначения и обладающие достаточной полнотой для выполнения требуемых функций. Образование программных секций может быть проиллюстрировано на примере написания исходного текста программы, когда программист пишет различные части программы на отдельных листах бумаги. Каждый лист бумаги можно сравнить с программной секцией. После написания программы программист может сам переупорядочить листы так, чтобы расположить код в соответствующем порядке. Например, определения могут находиться на одном листе, блоки данных - на втором, основная программа - на третьем, подпрограммы - на других листах. При написании программы программист время от времени может ссылаться на тот или иной лист бумаги. Завершив программу, программист может ввести исходный текст в ЭВМ с упорядоченных соответствующим образом листов.
Когда программа генерируется автоматически некоторой обрабатывающей программой, такой как макропроцессор или компиляторы Паскаля или Фортрана, часто бывает полезно разбить код программы на различные блоки. Это можно осуществить, сделав каждый блок программной секцией. В каждую программную секцию одновременно может быть введено по несколько строк исходного текста; строки текста, относящиеся к разным программным секциям, отделяются с помощью директивы .PSECT. Во время компоновки программы блоки кода упорядочиваются так, что они появляются в соответствующих программных секциях.
С точки зрения назначения адресов компоновщиком программные секции могут быть разделены на две основные категории. К первой категории относятся последовательно связываемые секции. Такие секции представляют собой локальные блоки в данном программном модуле, не используемые другими программными модулями. Эти секции имеют имена, позволяющие различать их между собой, но чаще всего имена используются только для того, чтобы связать эти секции. К другой категории программных секций относятся перекрывающиеся секции. Они подобны общим блокам в Фортране, содержат данные или инструкции, разделяемые несколькими программными модулями. Эти секции имеют глобальные имена, поэтому компоновщик будет выделять одну и ту же область памяти для одинаково поименованных секций, находящихся в других модулях.
Во время первого прохода компоновщик должен выделить память для программных секций. Вспомним, что словарь глобальных имён модуля содержит информацию о длине каждой программной секции и её типе. Последовательно связываемые секции располагаются одна за другой, а в случае перекрывающихся секций память выделяется для каждой секции, имеющей отличающееся имя. Закончив выделение памяти, компоновщик имеет полную карту распределения памяти для всей программы, которая может быть распечатана по запросу. Теперь рассмотрим второй проход компоновки.
БИБЛИОТЕКИ ПОДПРОГРАММ
Большинство операционных систем работают с библиотеками подпрограмм, предварительно ассемблированных или полученных после компиляции. Например, в ОС VAX/VMS имеются системные библиотеки, в которых содержатся следующие типы подпрограмм:
- Стандартные подпрограммы Паскаля, Фортрана или других языков, а также функции, подобные SIN, SQRT, ЕХР и т.д.
- Внутренние подпрограммы и функции Паскаля, Фортрана и других языков. Они вызываются при появлении более сложных операторов языка, таких как READ и WRITE. На самом деле некоторые мини-ЭВМ не имеют таких сложных операций, какие есть на ЭВМ семейства VAX. Поэтому для выполнения даже таких простых операций, как умножение и деление, могут потребоваться подпрограммы. Для того чтобы не спутать подпрограммы с подпрограммами, написанными пользователями, внутренние подпрограммы имеют необычные глобальные имена, в которые входят знаки подчёркивания или знаки доллара, например имя PAS$FV_OUTPUT.
- Системные подпрограммы. Эти подпрограммы могут быть вызваны из программ, написанных на языках высокого уровня или языке ассемблера, для выполнения специальных функций операционной системы VAX/VMS. Имеются подпрограммы, которые могут быть вызваны из программ, написанных на Паскале или Фортране, позволяющие выполнять функции, подобные большинству функций ввода-вывода, реализуемых с помощью макроинструкций, описанных в гл. 11. Например, функции ввода-вывода с очередями могут быть выполнены в программах на языках высокого уровня посредством вызова подпрограммы SYS$QIOW.
Такие подпрограммы собираются в объектный файл специального вида, особенности организации файла облегчают поиск в нём глобальных имён. Этот файл используется после завершения первого прохода компоновки. Если были обнаружены какие-либо неопределённые глобальные имена, то начинается поиск в библиотеке. Вспомним, что словари глобальных имён наряду с определениями имён содержат списки неопределённых глобальных имён.
Если в программе имеются какие-либо неопределённые глобальные имена, то в библиотеке производится поиск объектных модулей, в которых эти имена определены. При нахождении такие объектные модули добавляются к программе. Модули, не содержащие определения пропущенных глобальных имён, к программе не добавляются, поскольку, это увеличило бы длину программы больше, чем необходимо.
Тем не менее отметим, что добавляемые к программе модули могут сами иметь ссылки на неопределённые глобальные имена. Эти имена должны быть добавлены к списку поиска, и в этом случае может потребоваться включение в программу дополнительных модулей.
В операционной системе VAX/VMS существуют три способа подключения библиотечных подпрограмм. Первый способ применяется для подключения системных подпрограмм, таких как SYS$QIOW. Эти подпрограммы представляют собой постоянные резидентные части операционной системы; в системном пространстве памяти им назначены фиксированные адреса. Следовательно, компоновщик получает только ссылки на адреса подпрограмм. К программе не добавляется никакого кода.
Второй способ используется, когда в подпрограмму необходимо включать в код, генерируемый компоновщиком. Объём памяти, занимаемый программой, будет увеличен, чтобы, сохранить место для библиотечной подпрограммы. Копия скомпонованной программы помещается в файл выполняемого кода.
Третий способ занимает промежуточное положение между двумя первыми. В старых вычислительных системах второй способ применялся для всех несистемных подпрограмм. Это означало, что если имелось 100 программ, в которых использовалась подпрограмма вычисления квадратного корня, то необходимо было иметь 100 копий этих подпрограмм, занимающих пространство в файлах этих программ. Ещё хуже, если бы необходимы были также многочисленные копии больших по объёму подпрограмм ввода-вывода, автоматически вызываемых всякий раз, когда в программах на Паскале или Фортране встречались операторы WRITELN или PRINT или им подобные. Чтобы сохранить файловое пространство, для каждой из этих наиболее важных подпрограмм образуется только один выполняемый образ. Эти образы хранятся в библиотеке разделяемых образов. Во время подготовки программы пользователя к выполнению все необходимые разделяемые образы добавляются к выполняемому образу программы.
15.4. ФАЙЛЫ ВЫПОЛНЯЕМЫХ ОБРАЗОВ
Всякий раз, когда выполняется команда RUN, система будет загружать вашу программу, используя файл типа .EXE или иначе - файл выполняемого образа, сгенерированный компоновщиком. Поэтому файлы типа .EXE должны содержать всю необходимую информацию для загрузки и выполнения вашей программы. Формат файлов типа .EXE на самом деле достаточно сложный, так как файл включает значительный объём информации для изменения адресов, относящихся к разделяемым образам или используемых в них. Однако если это проигнорировать, то можно значительно упростить обсуждение. Чаще всего файлы типа .EXE являются образом, повторяющим байт в байт программу пользователя. Имеется два существенных исключения. Одно из них проявляется тогда, когда включаются разделяемые образы, другое - когда в программе есть большие неинициализированные массивы данных, такие как массивы, заданные директивой .BLKL, и т.п. Для сохранения файлового пространства файлы типа .EXE содержат коды для пропуска этих областей. Если не затрагивать вопросы, касающиеся разделяемых образов и больших массивов, то можно упростить формат файлов типа .EXE, сведя его к следующему. (Отметим, что данное обсуждение опирается на текущую версию ОС VAX/VMS, используемую во время написания книги. Нет гарантий, что рассматриваемый формат будет таким же, как здесь описано. Читателю рекомендуется получить дампы файлов типа .EXE и проверить формат этих файлов.)
Благодаря побайтовой организации файлов типа .EXE в них используется одна из простых структур записей. Файл типа .EXE представляет собой файл последовательного доступа с записями фиксированной длины. Длина фиксированных записей составляет 512 байтов; эти записи загружаются в 512-байтовые блоки памяти. (Отметим, что десятичное число 512 эквивалентно шестнадцатеричному числу 200, кроме того, это число соответствует длине физических блоков на большинстве внешних запоминающих устройств большой ёмкости ЭВМ VAX.)
Помимо текста программы в файле выполняемого образа содержится следующая управляющая информация:
- 1) длина программы;
- 2) начальный адрес программы;
- 3) длина программных секций и коды защиты для этих секций;
- 4) место расположения стека и других системных областей;
- 5) информация для отладчика (если требуется).
Данная информация имеет такую же структуру записей фиксированной длины, как и остальная информация в файле. Полный формат файла выполняемого образа приводится ниже.
- Заголовок образа. Эта запись содержит такую информацию, как старший адрес памяти, используемый для загрузки программы, начальный адрес, называемый также адресом передачи управления, и символьную строку - имя программы, определённое в директиве .TITLE. (Имя программы начинается с первого символа, следующего после директивы .TITLE. Длина имени программы, как и длина всех имён в ассемблере, ограничивается до 31 символа.) В записи заголовка содержатся также и другие данные, которые связывают эту запись с информацией, содержащейся в последующих блоках.
- Переменное число записей текста. Данные записи содержат побайтовое содержимое памяти, загружаемое загрузчиком. Загрузка программы начинается с адреса ^X200 и продолжается до тех пор, пока не будет считан старший адрес, как указано в записи заголовка.
- Записи вспомогательной информации. Записи содержат информацию о программных секциях и таблицу имён, используемых отладчиком.
Три основные порции информации, содержащиеся в записи заголовка, имеют следующий формат:
- Старший адрес. Адрес находится в длинном слове, расположенном со смещением ^X2C байтов от начала записи. Длинное слово задаёт старший адрес, используемый в тексте программы, и в действительности сообщает загрузчику, сколько записей текста необходимо считать.
- Адрес передачи управления. Адрес помещён в длинное слово, расположенное со смещением ^X34 байта от начала записи. Длинное слово задаёт адрес, который должен быть указан при вызове программы для того, чтобы начать её выполнение. Напомним, что программа пользователя вызывается с помощью инструкций CALLS или CALLG. Поэтому по адресу передачи управления должна находиться маска сохранения регистров, занимающая одно слово, за которой следует первая выполняемая инструкция программы пользователя.
- Имя программы. Имя программы представляет собой последовательность байтов, смещённую от начала записи на ^X4C байта. Первый байт последовательности задаёт число байтов имени. Этот указатель длины имени должен иметь значение меньше или равное 31. Все остальные байты являются символами в коде ASCII.
Такое упрощённое понимание структуры заголовка и записей текста достаточно, чтобы написать программу, которая может загрузить и выполнить программу пользователя (см. п. 6 упр. 15.2).
ЗАГРУЗКА В ВИРТУАЛЬНУЮ ПАМЯТЬ
В ЭВМ с традиционной архитектурой код программы из файла типа .EXE должен быть считан или загружен в память перед выполнением программы. Однако в архитектуре ЭВМ с виртуальной памятью процесс загрузки может модифицироваться, так как обычно загрузки в память программы целиком не требуется. Отметим, что в системе виртуальной памяти имеется таблица, в которой каждой странице соответствует своя запись. Каждая запись таблицы содержит следующую информацию (см. гл. 14).
- Является ли виртуальная страница активной и, таким образом, отображается ли она в настоящий момент времени на страницу реальной памяти.
- Если страница активна, то в какое место реальной памяти она отображается.
- Местонахождение блока, используемого для сохранения копии страницы, на дисковой системе.
Когда пользователь вводит команду RUN, ОС VAX/VMS запускает программу, называемую активатором образа. Активатор образа не загружает программу, а копирует страницы программы в специальную область виртуальной памяти на диске, при необходимости выполняя соответствующую модификацию. Как уже было отмечено, в программе может потребоваться модификация адресов. Если страница находится в программной секции, предназначенной только для чтения и не требующей модификации, страница может отображаться прямо в соответствующий блок файла типа .EXE. Активатор образа делает также неактивными отображения всех страниц программы в реальную память. Поэтому в начале выполнения программы сразу возникает прерывание по отсутствию страницы, обслуживаемое процедурой обмена страниц, которая в конечном счёте загружает программу пользователя.
15.5. ВЫПОЛНЕНИЕ ПРОГРАММЫ
РАБОТА ПРОЦЕССОРА
В гл. 3 цикл выполнения инструкции рассматривался в общем виде; здесь он будет рассмотрен более детально. На рис. 15.2 приведена блок-схема цикла выполнения инструкции для ЭВМ семейства VAX, на самом деле такой цикл выполняется на многих ЭВМ.
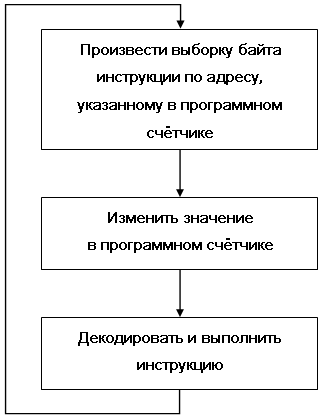
Рис. 15.2. Цикл выполнения инструкции
ЭВМ семейства VAX имеют инструкции, состоящие из различного числа байтов. Может показаться, что изменение программного счётчика не является вполне определённой операцией. Однако, как показано на блок-схеме, предполагается, что все инструкции имеют длину один байт, но при выполнении инструкции может потребоваться выборка дополнительных байтов из программы. Следовательно, изменение программного счётчика представляет собой следующую операцию: PC ← PC + 1.
Для декодирования инструкции по существу требуется получить однобайтовый код операции и использовать его, чтобы выбрать одну из 256 частей электронной схемы, необходимую для выполнения частных операций, определённых для данной инструкции. Однако если реализацию каждой инструкции осуществлять без учёта реализации других инструкций, то построить процессор было бы очень дорого. Для снижения экономических затрат при проектировании процессора необходимо принять во внимание, что многие инструкции имеют общие функции. Например, в большинстве инструкций ЭВМ VAX используются одни и те же режимы адресации. Поэтому некоторые функции, такие как адресация, могут быть реализованы для многих различных инструкций с помощью только одной части электронной схемы процессора. Работа таких частей электронной схемы очень похожа на работу подпрограмм.
Во время работы каждая инструкция активизирует выбранную последовательность действий, выполняемых различными обрабатывающими электронными схемами процессора. Эта выбранная для инструкции последовательность операций называется микропрограммой или микрокодом. Микропрограммы для некоторых инструкций могут быть очень сложными. Например, такие инструкции, как инструкции умножения, часто реализуются с помощью повторяющейся активизации электронных схем суммирования и сдвига. Таким образом, микропрограммы могут, подобно обычным программам, включать циклы. Конечно, использование циклов будет замедлять выполнение операций. Поэтому для достижения высокого быстродействия отдельные большие ЭВМ имеют в составе процессора дорогие быстродействующие электронные схемы умножения, выполняющие умножение двоичных чисел с помощью логических операций без циклов. Тем не менее такие инструкции, как POLYF или POLYD, являются слишком сложными, чтобы их можно было эффективно реализовать без циклов. В табл. 15.1 даны сравнительные оценки реализации умножения на различных ЭВМ.
| Быстродействие |
Стоимость |
Реализация |
Тип процессора |
|---|---|---|---|
Высокое |
Высокая |
Электронная схема |
VAX-11/780 |
Среднее |
Средняя |
Микропрограммная с циклами |
PDP-11/23 |
Низкое |
Низкая |
Программная с циклами |
Z80 или 6502 |
Чтобы упростить декодирование, инструкции часто разделяются на группы, а сходные числовые значения кода операции будут показывать принадлежность инструкции к группе. Например, рассмотрим следующий список кодов операций:
ADDF2 |
40 |
ADDF3 |
41 |
ADDD2 |
60 |
ADDD3 |
61 |
ADDB2 |
80 |
ADDB3 |
81 |
ADDW2 |
А0 |
ADDW3 |
А1 |
ADDL2 |
С0 |
ADDL3 |
С1 |
Применение числовых кодов операций позволяет упростить процесс декодирования, что, в свою очередь, может снизить стоимость и повысить быстродействие ЭВМ. Однако, становясь более мощными, современные ЭВМ должны иметь большое число сложных инструкций, и тогда при реализации приходится искать компромисс. В конечном счёте числовые значения кодов операций могут потерять свой очевидный смысл, что часто и происходит. В этом случае процессор использует код операции как адрес постоянной памяти, в которой содержится таблица перевода, преобразующая 8-битовые коды операций в более длинные коды, а эти коды уже непосредственно устанавливают связь с микрокодом для декодируемой инструкции.
ЭВМ семейства VAX имеют более 256 инструкций. Такое число инструкций означает, что недостаточно иметь однобайтовый код операции для однозначной идентификации всех инструкций. Решение состоит в том, что коды операций ^XFD, ^XFE и ^XFF используются как переключающие коды, которые сообщают процессору, чтобы он произвёл выборку второго байта для второго уровня декодирования. Данный подход эффективно позволяет увеличивать число кодов операций без каких-либо особых ограничений. В настоящее время на ЭВМ семейства VAX расширение кодов операций применяется довольно редко. Все 2-байтовые коды операций используются для выполнения операций над числами с плавающей точкой в форматах тип G и Н, в качестве переключающего кода служит ^XFD (см. гл. 12).
ПОЗИЦИОННО-НЕЗАВИСИМЫЙ КОД
Одним из особых преимуществ архитектуры ЭВМ семейства VAX является возможность использования программного счётчика как обычного регистра смещения. Это позволяет адресовать данные и инструкции относительно текущего места выполнения программы. Преимущество заключается в том, что если программа адресует свои собственные ячейки относительно текущего значения в программном счётчике, то относительные адреса не изменяются при перемещении программы.
Например, предположим, что при выполнении инструкции программы в программном счётчике находится значение ^X0740 и должен быть осуществлён доступ к данным, расположенным по адресу ^X0A14; смещение от текущего значения программного счётчика к этому адресу равно ^X0A14 - ^X0740 = ^X03D4. Фактически тот же самый способ адресации используется на ЭВМ семейства VAX в режиме CF (см. гл. 7). Теперь, если программа перемещается на ^X0200 байтов, то адрес в программном счётчике и адрес данных соответственно изменяется на ^X0940 и ^X0C14, но разница между адресами останется прежней - ^X03D4. В результате данная программа может быть загружена в какое-либо место памяти без требования модификации этой отдельной инструкции. Если вся программа написана таким образом, то говорят, что её код позиционно-независимый. Для того чтобы код программы был позиционно-независимым, программист должен специально следить за тем, чтобы применялись только те инструкции и режимы адресации, которые являются позиционно-независимыми. Следующий набор правил отмечает наиболее важные моменты.
Правило 1. Адресация ячеек программы. Как показано выше, доступ ко всем адресам программы должен осуществляться с помощью режима относительной адресации. Однако так как данный режим адресации является обычным режимом, то не накладывается никаких специальных требований. Инструкция MOVL A,B работает правильно.
Правило 2. Адресация фиксированной области памяти или регистров устройств, имеющих фиксированные адреса. Режим относительной адресации больше не срабатывает, так как адрес, получаемый при сложении значения в регистре PC с фиксированным смещением, изменится при перемещении программы. Однако можно применять режим абсолютной адресации, поскольку он требует указания исполнительного фиксированного адреса. Режим абсолютной адресации может быть задан, если поместить знаки @# перед адресом. Например, предположим, что адреса PORG и PLOC фиксированы в памяти, а адрес A находится в самой программе. В этом случае обе инструкции TSTB @#PORG и MOVB A,@#PLOC являются позиционно-независимыми.
Правило 3. Инструкции условных и безусловных переходов. В инструкциях условных переходов адресация осуществляется относительно программного счётчика и перекрывает небольшой диапазон адресов, поэтому не возникает дополнительных проблем. В инструкциях безусловных переходов используются обычные операнды и поэтому применяются режимы либо относительной, либо абсолютной адресации, в зависимости от того, осуществляется переход внутри самой программы или в фиксированное место в памяти.
Правило 4. Адресация массивов в программе. Массивы вызывают особую сложность, поскольку в инструкциях с индексным или регистровым косвенным режимами адресации требуется исполнительный адрес. Вспомним, что в гл. 7 рассматривались несколько способов доступа к элементам массива. Индексный режим адресации, как, например, в инструкции CLRB A[R0], будет позиционно-независимым, даже если адрес A является переместимым, поскольку исполнительный адрес вычисляется в два приёма. Сначала вычисляется адрес A как смещение относительно текущего значения регистра PC, после чего он складывается с содержимым регистра R0 для получения доступа к индексированному элементу массива. В конце гл. 7 были представлены такие режимы адресации, как косвенные, режимы со смещением, а также режим с автоувеличением. В этих режимах адрес помещается в регистр общего назначения. Отметим, что обычным способом загрузки адреса в регистр является следующий:
MOVAB A,R0
Эта инструкция позиционно-независимая, если адрес A переместимый; если адрес A - абсолютный, то инструкцию следует написать так:
MOVAB @#A,R0
Поскольку такой способ адресации поддерживается на ЭВМ VAX, этим правилам легко следовать и трудно написать программу, которая не была бы позиционно-независимой. Тем не менее требуется тщательно следить за данными. В таких массивах данных, как дескрипторы и списки аргументов программ, часто появляются адреса. Если переместимые адреса помещаются в массивы данных, то программа не будет полностью позиционно-независимой. Например, программа не будет позиционно-независимой, если в ней содержится директива .ASCID. Следует избегать применения директивы .ASCID, употребляя взамен директиву .ASCII и формируя дескриптор во время выполнения. Например, могло быть сделано следующее:
MSGD: .WORD 20$-10$,0 .LONG 0 10$: .ASCII "ТЕКСТ СООБЩЕНИЯ" 20$: . . . . MOVAB MSGD+8,MSGD+4 . . .
Как показано в этом фрагменте, инструкция MOVAB позиционно-независимая. С помощью этой инструкции соответствующий адрес помещается в дескриптор. Чтобы избежать этого и упростить написание программ, ОС VAX/VMS обеспечивает для файлов типа .EXE последнюю перед загрузкой модификацию, позволяя использовать для разделяемых образов директивы .ASCID и .ADDRESS. В результате эти директивы могут использоваться в позиционно-независимых (РIС) программных секциях, несмотря на то, что, строго говоря, такие директивы не являются позиционно-независимыми.
Позиционно-независимый код может быть весьма полезен для программ операционной системы. Например, в ОС VAX/VMS системные программы часто обладают способностью загружаться в любое место памяти туда, где есть свободное пространство. Многие из этих программ, такие как программы обслуживания устройств ввода-вывода и программы обслуживания пользователей, при необходимости динамически вызываются в память на любое свободное место.
УПРАЖНЕНИЯ 15.2
- Разработайте формат файлов с записями переменной длины, в котором вместо указателей длины записей использовались бы управляющие символы. Для байтов данных должны быть разрешены любые комбинации битов.
- Напишите программу, осуществляющую запись и чтение файлов в формате, разработанном вами в п. 1.
- Образуйте несколько файлов с различной структурой записей. Это может быть выполнено с помощью простой программы на Фортране, где в операторе OPEN задаются различные параметры, или с помощью программы, написанной на языке ассемблера, использующей различные макровызовы $FAB и $RAB. После этого, воспользовавшись командой DUMP/HEADER/NOFORMATED, посмотрите управляющие блоки файлов. Попробуйте определить предназначение различных управляющих кодов, используемых в управляющем блоке, и письменно изложите ваши предположения. Проверьте их, получив дамп других файлов.
- Напишите программу, которая считывает дампы, образованные по команде DUMP, и распечатывает содержимое файла в его первоначальном виде. Программа должна работать с обычными символьными файлами, какие используются для хранения исходного текста программ. Ваша программа может быть написана либо на языке ассемблера, либо на языке высокого уровня. Заметим, что в программе должна быть заложена возможность пропуска заголовков страницы и другой, не относящейся к делу информации, которая может присутствовать в дампе.
- Напишите программу, имеющую позиционно-независимый код. Программа должна распечатывать несколько строк сообщений для того, чтобы можно было понять, что она работает. После вывода сообщений программа должна скопировать сама себя в массив, размещённый в какой-то области памяти, затем заполнить нулями область памяти, в которой она находилась первоначально, и передать управление на перемещённый адрес начала программы, чтобы вновь выполнить распечатку сообщения, позволяющего убедиться, что код программы действительно позиционно-независимый. Отметим, что области данных также следует перемещать вместе с программой. (См. замечания по использованию директивы .ASCID в конце последнего раздела данной главы.) Особо отметьте следующее: для того чтобы код, порождаемый макроинструкциями $RAB и $FАВ, был позиционно-независимым, все параметры в макроинструкциях, представляющих собой адреса, должны быть помещены в блоки доступа во время выполнения программы. К таким параметрам относятся NAM=<FILE.XYZ> и FAB=FABLOC.
- Напишите программу, в начале которой расположен большой пустой массив, например такой, как .BLKL 5000. После компоновки программы он будет находиться по адресу ^X200. Напишите программу, которая могла бы считать файл типа .EXE простой программы, поместить записи текста этой программы в массив, начинающийся с адреса ^X200, и выполнить считанную программу. В связи с тем, что обычно настройка программы осуществляется так, чтобы программа начиналась с адреса ^X200, загруженную в массив программу для выполнения нужно разместить правильным образом.
| < НАЗАД | ОГЛАВЛЕНИЕ | ВПЕРЁД > |