ГЛАВА 7. МАССИВЫ
7.1. ВВЕДЕНИЕ
Большинство читателей знакомы с понятием массива, которое используется в языках программирования высокого уровня, таких как Паскаль и Фортран. Программист имеет некоторую совокупность данных, которую требуется определённым образом обработать. Более того, программист хочет иметь одновременно всю совокупность данных в памяти. В этой главе будет показано, как создаются и обрабатываются массивы в программах на языке ассемблера для ЭВМ семейства VAX. Кроме того, будет описан полный набор режимов адресации, который имеют ЭВМ семейства VAX.
Одним из примеров задач с использованием массивов является сортировка чисел в возрастающем порядке. Поскольку действительный порядок вводимых чисел предположительно неизвестен, нельзя распечатать ни одно число, пока не будут введены все числа. Кроме того, последнее введённое число может оказаться наименьшим и, следовательно, должно быть напечатано первым. На рис. 7.1,а и б приводятся примеры такой программы, написанной на Паскале и Фортране. В программе осуществляется ввод списка из 20 чисел, выполняется сортировка этих чисел по возрастанию и в конце упорядоченный список выводится на печать. Обратите внимание, что программа разделяется на три части: ввод чисел, сортировка и печать. Эти три части программы выделены комментариями. Используемый в программе метод сортировки представляет собой один из вариантов известного алгоритма сортировки выбором. Если читатель ещё не знаком с методом сортировки, ему предлагается в качестве упражнения подробно разобрать эти программы.
(а) Паскаль
PROGRAM SORT(INPUT,OUTPUT); VAR J,K,L,M : INTEGER; LIST : ARRAY[1..20] OF INTEGER; BEGIN (* ВВОД НЕУПОРЯДОЧЕННЫХ ЧИСЕЛ *) FOR J : = 1 TO 20 DO READLN (LIST[J]); (* СОРТИРОВКА ЧИСЕЛ *) FOR L : = 1 TO 19 DO BEGIN FOR K:=L+1 TO 20 DO BEGIN IF (LIST[L] > LIST[K]) THEN BEGIN M: = LIST[L]; LIST[L]:=LIST[K]; LIST[K]:=M; END; END; END; (* ПЕЧАТЬ УПОРЯДОЧЕННЫХ ЧИСЕЛ *) FOR J:=1 TO 20 DO WRITELN(LIST[J]); END.
(б) Фортран
PROGRAM SORT
INTEGER LIST(1:20), J, K, L, M
С ВВОД НЕУПОРЯДОЧЕННЫХ ЧИСЕЛ
READ *,(LIST(J),J=1,20)
С СОРТИРОВКА ЧИСЕЛ
DO 20 L=1,19
DO 10 K=L+1,20
IF (LIST(L).GT.LIST(K)) THEN
M=LIST(L)
LIST(L)=LIST(K)
LIST(K)=M
END IF
10 CONTINUE
20 CONTINUE
С ПЕЧАТЬ УПОРЯДОЧЕННЫХ ЧИСЕЛ
PRINT *,(LIST(J),J=1,20)
STOP
END
Рис. 7.1. Программа сортировки
Первый оператор в обоих вариантах программы - это невыполняемый оператор, сообщающий компилятору, сколько ячеек памяти должно быть выделено для массива LIST.
Как было показано ранее, в программе на языке ассемблера необходимо зарезервировать ячейки памяти, предназначенные для данных, что обычно делается с помощью директивы ассемблера .BLKL 1. В следующем разделе будет рассмотрено выделение памяти под массивы.
Обратите внимание, что в программах на языках Фортран и Паскаль в различных операциях основной части программы идентификатор переменной LIST используется вместе с индексом, который указывает на определённый элемент массива. Это требуется потому, что обращение всё время осуществляется к отдельному элементу массива, а не ко всему массиву. Это справедливо и для языка ассемблера. Хотя некоторые вычислительные машины, в частности и ЭВМ семейства VAX, имеют инструкции, позволяющие выполнить пересылку всего массива целиком, большинство операций нижнего уровня работают в один момент времени только с одной ячейкой памяти. Поэтому необходимы средства для указания отдельного элемента массива. Об этом и будет рассказано в следующем разделе.
7.2. МАССИВЫ В ПРОГРАММАХ НА ЯЗЫКЕ АССЕМБЛЕРА
РАСПРЕДЕЛЕНИЕ ПАМЯТИ
Как было сказано выше, при работе с массивами необходимы некоторые средства для резервирования ряда ячеек памяти. Хотя это можно сделать по-разному, проще всего использовать блок последовательно расположенных ячеек памяти. Ячейки в блоке соответствуют последовательно расположенным элементам массива.
В языке ассемблера VAX для резервирования блока памяти используются директивы .BLKL, .BLKW или .BLKB. Ранее в поле операндов этих директив указывалось значение 1, которое показывало, что резервируется одно длинное слово, слово или байт. Для массива, чтобы зарезервировать больший блок памяти, в директиве может быть указано большее число. Тогда ассемблер в этом месте программы зарезервирует пространство для заданного числа элементов данных. Например, по директиве .BLKL 10 было бы выделено десять длинных слов, размещённых одно после другого (см. рис. 7.2).
XYZ: .BLKL 10 |
XYZ: .BLKL 1 ;XYZ(1) |
Рис. 7.2. Директива .BLKL
Для того чтобы можно было обращаться к массиву, массив должен иметь символическое имя. Для этого перед директивой .BLKL помещается метка XYZ. Как описывалось в гл. 4, это символическое имя (символический адрес) XYZ вводится в таблицу имён, определяемых пользователем, вместе с текущим значением счётчика адресов. В результате символический адрес XYZ является адресом первого длинного слова массива. Директива ассемблера .BLKL 20 вызывает 20-кратное прибавление к содержимому счётчика адресов числа 4, т.е. увеличивает его на 80.
АДРЕСНЫЕ ВЫРАЖЕНИЯ
После того, как выделена память под массив, возникает проблема адресации определённого элемента этого массива. С первым элементом массива все просто, так как имя массива указывает адрес первого элемента массива. Поэтому первый элемент массива XYZ можно было бы очистить, выполняя инструкцию CLRL XYZ. Однако это не решает проблему доступа к другим элементам массива, таким как второй, третий и т.д.
Одним из решений этой проблемы является использование адресных выражений. Поскольку длинное слово занимает 4 байта, адрес второго элемента массива XYZ на четыре больше адреса XYZ. Аналогично третий и четвёртый элементы имеют адреса на 8 и 12 больше, чем адрес XYZ. Следовательно, можно ссылаться на эти адреса, используя символические выражения XYZ+4, XYZ+8 и XYZ+12.
Очистить содержимое первых четырёх элементов массива XYZ можно с помощью следующих инструкций:
CLRL XYZ CLRL XYZ+4 CLRL XYZ+8 CLRL XYZ+12
Обратите внимание, что в выражениях языка ассемблера символическое имя XYZ всегда означает адрес XYZ и никогда - содержимое ячейки с этим адресом, что очень важно для понимания инструкций типа MOVL XYZ+4,A. Внешне это похоже на операторы языков Паскаль или Фортран A:=XYZ+4; или A=XYZ+4. Однако по сути это разные вещи, так как в данном случае не подразумевается сложение содержимого XYZ с числом 4, а нужен адрес ячейки, который на 4 больше адреса XYZ. Поэтому здесь аналогия может быть проведена с оператором языков Паскаль и Фортран A := XYZ[2]; или A = XYZ(2).
Заметим, что адресные выражения могут использоваться в языке ассемблера везде, где может быть символическое имя или число. Выражение может быть довольно сложным, но в результате его вычисления должно получаться осмысленное значение - адрес или числовая константа. Подробнее это будет описано в гл. 10. Пока ограничимся наиболее часто встречающимися выражениями - адрес плюс-минус одно или более чисел или символических имён, представляющих собой числовые константы.
Использование адресных выражений очень важно при работе с массивами, но существует серьёзное ограничение. Эти выражения вычисляются во время ассемблирования и поэтому не могут включать какие-либо числа, которые могут быть изменены во время выполнения программы. Это означает, что хотя с их помощью можно обращаться к определённым элементам массива, таким как XYZ[1], XYZ[2] и т.д., но нельзя обратиться к неизвестному заранее (произвольному) элементу массива, такому как XYZ[J]. Следовательно, хотя можно было бы очистить массив, выполнив последовательность инструкций CLRL, но пока ещё не рассматривались средства, чтобы сделать это в цикле.
РЕГИСТРОВЫЙ КОСВЕННЫЙ РЕЖИМ
Необходимо иметь средства, по действию аналогичные адресным выражениям, позволяющие вычислять адрес во время выполнения программы. Для этого большинство современных ЭВМ имеют специальные режимы адресации. Адрес, который используется для выборки или занесения информации в память, называется исполнительным адресом. Например, в режиме относительной адресации для получения исполнительного адреса значение смещения складывается с содержимым программного счётчика. Архитектура ЭВМ VAX позволяет вычислять исполнительный адрес с помощью разных режимов адресации. Одним из простейших является регистровый косвенный режим. Для применения такого режима адресации значение адреса вычисляется во время выполнения программы и помещается в регистр. Затем в случае регистровой косвенной адресации значение, находящееся в регистре, используется как адрес операнда, т.е. исполнительный адрес.
XYZ: .BLKL 50 ; МАССИВ ЭЛЕМЕНТОВ CLEAR: MOVAL XYZ,R0 ; R0 - РЕГИСТР УКАЗАТЕЛЬ АДРЕСА CLRL R1 ; R1 - СЧЁТЧИК ЦИКЛА 10$: CLRL (R0) ; ОЧИСТИТЬ ЭЛЕМЕНТ МАССИВА ADDL2 #4,R0 ; УВЕЛИЧИТЬ УКАЗАТЕЛЬ AOBLSS #50,R1,10$ ; ПОВТОРЯТЬ В ЦИКЛЕ,ПОКА НЕ БУДУТ ; ОЧИЩЕНЫ 50 ЭЛЕМЕНТОВ МАССИВА
Рис. 7.3. Режим регистровой косвенной адресации
В ЭВМ VAX 15 из 16 регистров общего назначения (а именно R0 - R11, AP, FP и SP) могут использоваться для регистровой косвенной адресации. (Регистр 15 - программный счётчик - нельзя применять в этом режиме.) Для обозначения режима регистровой косвенной адресации в языке ассемблера операнд в инструкции записывается как имя регистра, заключённое в круглые скобки. Например, в инструкции CLRL (R3) задана косвенная адресация с использованием регистра 3. Исполнительным адресом является значение, содержащееся в этом регистре общего назначения. Если регистр 3 содержит адрес ^X00001000, то будет очищено содержимое длинного слова, начинающееся с адреса ^X1000.
Рассмотрим для примера действие инструкции CLRL (R3) на уровне машинного языка. Инструкция после её трансляции в машинный код будет занимать только 2 байта - один для кода операции и один для спецификатора операнда. В машинном коде инструкция будет выглядеть следующим образом:
63 D4
Инструкция CLRL имеет код операции ^XD4. Байт ^X63 обозначает косвенную адресацию с использованием регистра R3. (Код ^X6 задаёт регистровый косвенный режим, а ^X3 - регистр 3.)
Теперь, прежде чем описать действие этой инструкции, необходимо знать содержимое регистра R3. Предположим, что в момент выполнения этой инструкции регистр R3 содержит ^X00001E84. Поскольку исполнительный адрес равен ^X00001E84, инструкция CLRL очищает (сбрасывает в 0) содержимое длинного слова с адресом ^X1E84. Надо отметить, что содержимое регистра R3 не изменяется при выполнении инструкции CLRL и после выполнения этой инструкции в регистре R3 остаётся значение ^X00001E84.
На рис. 7.3 приведён фрагмент программы, в котором очищается массив из 50 длинных слов. Обратите внимание:
- В регистр R0 загружается начальный адрес массива XYZ с помощью новой инструкции MOVAL (переслать адрес длинного слова).
- При каждом проходе цикла к содержимому регистра R0 прибавляется число 4, полученный адрес указывает на следующее длинное слово массива.
- Ещё один регистр, R1, используется для счёта числа повторений. Это может показаться избыточным, и в самом деле, как будет показано, второй регистр не понадобится, когда будут рассмотрены дополнительные режимы адресации.
СЕМЕЙСТВО ИНСТРУКЦИЙ MOVAL
Инструкция MOVAL (см. программу на рис. 7.3) - это только один представитель семейства инструкций, разработанных специально для загрузки адресов, используемых впоследствии в режимах адресации, таких как регистровая косвенная. Инструкция MOVAL отличается от инструкции MOVL тем, что MOVL пересылает содержимое длинного слова по указанному месту назначения, a MOVAL пересылает адрес длинного слова. Инструкция MOVAL - это один член семейства инструкций пересылки адреса, которое включает в себя:
| Мнемоника |
Значение |
|---|---|
MOVAB |
Переслать адрес байта |
MOVAW |
Переслать адрес слова |
MOVAL |
Переслать адрес длинного слова |
MOVAQ |
Переслать адрес 64-битового квадраслова |
MOVAO |
Переслать адрес 128-битового октаслова |
Поскольку адрес на ЭВМ VAX представляет собой 32-битовое двоичное число, любая из этих пяти инструкций выполняет пересылку 32-битового значения по адресу второго операнда, имеющего формат длинного слова. Может показаться странным, зачем нужно пять таких инструкций, если адрес всегда остаётся адресом, независимо от того, указывает он на байт, слово, длинное слово и т.д.
Фактически программа на рис. 7.3 будет работать так же, если инструкцию MOVAL заменить на инструкцию MOVAB. Однако, когда позднее в этой главе будут рассмотрены более сложные режимы адресации, станет ясно, зачем нужно столько инструкций.
Чтобы понять смысл инструкций пересылки адреса, необходимо рассмотреть, что произойдёт при выполнении следующих трёх инструкций:
MOVL A,R0 MOVL #A,R0 MOVAL A,R0
Предположим, что символическое имя A определено в ассемблерной программе следующим образом и при ассемблировании символическому адресу A был назначен адрес ^X00000444:
A: .LONG ^X00112233
Если компоновщик настроит программный модуль, содержащий имя A, так, что адресом начала этого модуля станет ^X0200, то во время выполнения символическому имени A будет соответствовать адрес ^X00000444 плюс ^X0200 или ^X00000644 (см. о перемещении адресов в гл. 4). В машинном коде длинное слово с адресом A могло бы выглядеть следующим образом:
| Содержимое | Адрес |
|---|---|
00112233 |
00000644 |
По первой инструкции, MOVL A,R0, будет выполняться пересылка содержимого длинного слова A в регистр R0, так что в результате в регистре R0 будет содержаться значение ^X00112233. Поскольку эта инструкция использует одну из форм относительной адресации для операнда A, то при перемещении программы на адрес ^X0200 не требуется никакой модификации программы. (Если адрес A и инструкция MOVL A, R0 находятся в одном модуле, то расстояние между ними не меняется при перемещении модуля.)
Во второй инструкции MOVL #A,R0 используется непосредственная адресация для "константы" A, которой соответствует в таблице имён значение ^X00000444. Поэтому длинное слово ^X00000444 становится частью инструкции. Когда компоновщик будет настраивать программу на адрес ^X0200, то он прибавит ^X0200 к значению длинного слова, содержащемуся в инструкции, так что оно станет равно ^X00000644. В результате эта инструкция будет пересылать значение ^X00000644 (адрес A во время выполнения) в регистр R0.
По третьей инструкции, MOVAL A,R0, также пересылается значение ^X00000644 в регистр R0. Однако эта инструкция использует одну из форм относительной адресации для вычисления адреса A, поэтому при настройке программы эту инструкцию не надо модифицировать.
На многих ЭВМ, таких как ЭВМ семейства PDP-11, инструкции, подобные MOVL #A,R0, используются для получения адресов внутри модуля. Все такие адреса должны модифицироваться, если программа перемещается. В отличие от этого архитектура ЭВМ VAX ориентирована на то, чтобы упростить разработку позиционно независимых программ, которые могут без всякой модификации размещаться в любом месте памяти. Именно для этого в набор инструкций VAX включена группа инструкций MOVAL. Поэтому считается, что использование непосредственной адресации с символическими адресами, как в инструкции MOVL #A,R0, является плохим стилем программирования.
ПРОГРАММА СОРТИРОВКИ
В качестве последнего примера этого раздела перепишем программу рис. 7.1 на языке ассемблера (рис. 7.4). Этот пример не включает ввод и вывод, а содержит только программу сортировки. В программе на языке ассемблера регистры R3 и R4 используются как счётчики циклов L и K соответственно. Однако в программе на языке высокого уровня переменная L принимает значения 1-19, а содержимое регистра R3 в ассемблированной программе изменяется от 0 до 18. То же замечание справедливо для K и R4. В ассемблерной программе регистр R2, подобно переменной M в программе на языке высокого уровня, служит как временная память для перестановки местами двух элементов. Для выборки элементов массива применяется регистровая косвенная адресация с использованием регистров R0 и R1. Обратите внимание, что для загрузки адреса LIST в регистр R0 используется инструкция MOVAL.
SIZE=20 LIST: .BLKL SIZE ; ПАМЯТЬ ВЫДЕЛЕННАЯ ДЛЯ МАССИВА . . . SORT: MOVAL LIST,R0 ; R0 - УКАЗАТЕЛЬ НА ЛЕВЫЙ ЭЛЕМЕНТ МАССИВА CLRL R3 ; R3 - СЧЁТЧИК ВНЕШНЕГО ЦИКЛА,L 10$: MOVL R0,R1 ; ЗНАЧЕНИЕ ПРАВОГО УКАЗАТЕЛЯ В R1 РАВНО ADDL2 #4,R1 ; ЗНАЧЕНИЮ ЛЕВОГО УКАЗАТЕЛЯ + 4 MOVL R3,R4 ; R4 - СЧЁТЧИК ВНУТРЕННЕГО ЦИКЛА,К INCL R4 ; ЕГО НАЧАЛЬНОЕ ЗНАЧЕНИЕ L+1 20$: CMPL (R0),(R1) ; СРАВНИТЬ ЛЕВЫЙ И ПРАВЫЙ ЭЛЕМЕНТЫ МАССИВА BLEQ 30$ ; ЕСЛИ МЕНЬШЕ ИЛИ РАВНО,ПРОДОЛЖИТЬ ЦИКЛ MOVL (R0),R2 ; ИНАЧЕ ПОМЕНЯТЬ МЕСТАМИ MOVL (R1),(R0) ; ДВА ЭЛЕМЕНТА МАССИВА LIST, MOVL R2,(R1) ; ИСПОЛЬЗУЯ R2 КАК ВРЕМЕННУЮ ПАМЯТЬ,М 30$: ADDL2 #4,R1 ; УВЕЛИЧИТЬ ПРАВЫЙ УКАЗАТЕЛЬ AOBLSS #SIZE,R4,20$ ; ПОВТОРЯТЬ В ЦИКЛЕ ДО ЗАВЕРШЕНИЯ ADDL2 #4,R0 ; УВЕЛИЧИТЬ ЛЕВЫЙ УКАЗАТЕЛЬ AOBLSS #SIZE-1,R3,10$ ; ПОВТОРЯТЬ В ЦИКЛЕ ДО ЗАВЕРШЕНИЯ
Рис. 7.4. Программа сортировки на языке ассемблера
УПРАЖНЕНИЯ 7.1
- Пусть регистры R0, R1 и R2 содержат
следующие значения, представленные в шестнадцатеричном виде:
R0
^X00001111
R1
^X00000E24
R2
^X0000FFC4
а символические имена ABC, PQW и XYZ соответствуют следующим адресам:
ABC
^X00001000
PQW
^X0000C4E0
XYZ
^XFFFFFFF8
Какими будут исполнительные адреса в следующих (взятых по отдельности) инструкциях, т.е. какие ячейки будут очищены при их выполнении?
а. CLRL
PQW
б. CLRL
PQW+24
в. CLRL
ABC+^XE4
Г. CLRL
ABC+300
д. CLRL
(R0)
e. CLRL
XYZ+1046
ж. CLRL
(R1)
з. CLRL
XYZ+^X300
и. CLRL
(R2)
к. CLRL
XYZ+100
- Преобразуйте каждую из инструкций п. 1 упр. 7.1 в машинный код, считая, что инструкция расположена, начиная с адреса ^X00000346.
- Преобразуйте фрагмент программы рис. 7.4 в полностью законченную программу сортировки. Используйте подпрограммы RNUM и PNUM из приложения Б для организации ввода и вывода. Выполните программу с произвольными исходными данными.
- Блок-схема, представленная ниже, описывает алгоритм сортировки, который
называют методом пузырьковой сортировки.
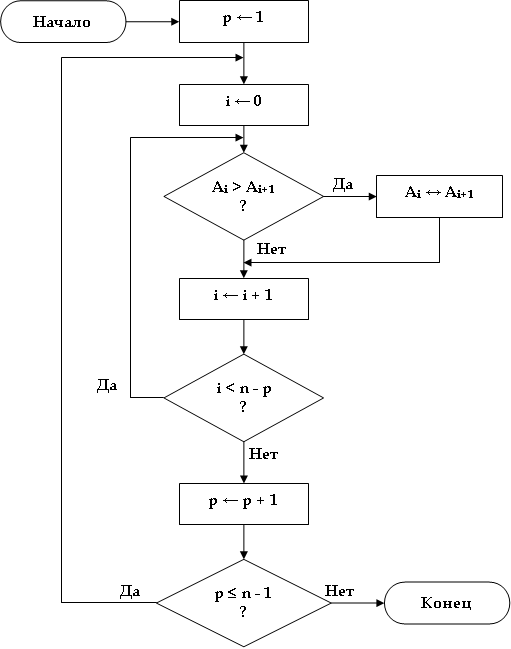
* N - число элементов, подлежащих сортировке
* А - массив данных, подлежащих сортировкеСтруктурная схема алгоритма пузырьковой сортировки
- а. Как работает эта программа сортировки? Приведите пример с четырьмя или пятью элементами.
- б. Чем отличается эта программа от программы сортировки рис. 7.4?
- в. Какой из методов более эффективен и в чём их различие?
- г. Какие преимущества и недостатки можно выделить при сравнении этих двух методов?
- Напишите программу на языке ассемблера (аналогичную рис. 7.4), реализующую алгоритм пузырьковой сортировки п. 1 упр. 7.1.
- Напишите (добавив подпрограммы ввода-вывода из приложения Б) полную программу, использующую метод пузырьковой сортировки, и выполните её.
7.3. ДРУГИЕ РЕЖИМЫ АДРЕСАЦИИ
АДРЕСАЦИЯ С АВТОУВЕЛИЧЕНИЕМ
Как было видно из предыдущих примеров, когда при просмотре массива применялась регистровая косвенная адресация, необходимо было корректировать значение указателя в регистре, прибавляя к нему на очередном шаге цикла некоторое число. Если массив состоит из длинных слов, то следует для перехода к следующему элементу массива увеличивать значение указателя на 4. Чтобы облегчить это и повысить эффективность программ, ЭВМ VAX имеют режим адресации, при котором такое увеличение производится автоматически. Такой режим называется режимом с автоувеличением. Режим с автоувеличением весьма сходен с регистровым косвенным режимом в том, что в некотором регистре содержится адрес операнда. Отличие заключается в том, что после выполнения инструкции адрес, содержащийся в регистре, увеличивается на четыре или на число байтов в длинном слове. В языке ассемблера режим с автоувеличением обозначается как заключённое в скобки имя регистра, за которыми следует знак плюс. Например, в следующей инструкции CLRL задан режим с автоувеличением с использованием регистра 0.
CLRL (R0)+
Результат выполнения этой инструкции точно такой же, как и результат выполнения следующей пары инструкций:
CLRL (R0) ADDL2 #4,R0
Однако следует отметить две особенности. Первая заключается в том, что при использовании режима с автоувеличением требуется меньше инструкций. Вторая - в том, что при этом режиме коды условий определяются операндом инструкции, а не операцией автоувеличения или содержимым регистра.
В качестве примера применения режима с автоувеличением разберём программу, выполняющую суммирование элементов массива, состоящего из 20 длинных слов. На рис. 7.5 показано два варианта реализации этой программы - с регистровым косвенным режимом и режимом с автоувеличением. Как уже говорилось, отличие между этими двумя программами состоит в том, что при использовании режима с автоувеличением не требуется инструкция ADDL2 #4,R0. Это делает программу короче, яснее, более простой в написании и значительно эффективнее. (Обратите внимание, что уменьшается число инструкций в цикле.)
| (а) Вариант с регистровой, косвенной адресацией | (б) Вариант с использованием режима с автоувеличением |
|---|---|
SIZE=20 SUM: .BLKL 1 DATA: .BLKL SIZE . . . SUMV1: MOVAL DATA,R0 CLRL R1 CLRL SUM 10$: ADDL2 (R0),SUM ADDL2 #4,R0 AOBLSS #SIZE,R1,10$ |
SIZE=20 SUM: .BLKL 1 DATA .BLKL SIZE . . . SUMV2: MOVAL DATA,R0 CLRL R1 CLRL SUM 10$: ADDL2 (R0)+,SUM AOBLSS #SIZE,R1,10$ |
Рис. 7.5. Две программы суммирования 20 чисел
При выполнении инструкции ADDL2 (R0)+,SUM адрес, содержащийся в регистре R0, увеличивается на 4, поскольку длинное слово занимает 4 байта. Чтобы использовать режим с автоувеличением для работы с массивами данных любого типа, значение увеличения определяется кодом операции. Например, в инструкции ADDB2 (R0)+,SUM адрес в регистре R0 увеличивается на 1, а в инструкции ADDW2 (R0)+,SUM адрес в регистре R0 увеличивается на 2. Аналогично в инструкциях, работающих с квадрасловами или октасловами, адрес в регистре увеличивается на восемь или шестнадцать соответственно.
Этим, в частности, объясняется, почему имеется несколько инструкций MOVA. Инструкции семейства MOVA могут использоваться с любым режимом адресации. Таким образом, допустима инструкция MOVAL (R0)+,R3. По этой инструкции в регистр R3 будет занесён адрес, содержащийся в регистре R0 (а не содержимое длинного слова, расположенного по этому адресу). Предположим, например, что до выполнения этой инструкции в регистре R0 содержится адрес А некоторого длинного слова. После выполнения инструкции MOVAL (R0)+,R3, в регистр R3 будет помещён адрес А указанного длинного слова, а в регистр R0 - адрес А+4 следующего длинного слова. Чтобы обеспечить выполнение таких адресных вычислений в соответствии с различными форматами данных в инструкциях семейства MOVA, при автоувеличении используются следующие приращения:
| Инструкция |
Приращение R0 |
|
|---|---|---|
MOVAB |
(R0)+,R3 |
1 |
MOVAW |
(R0)+,R3 |
2 |
MOVAL |
(R0)+,R3 |
4 |
MOVAQ |
(R0)+,R3 |
8 |
MOVAO |
(R0)+,R3 |
16 |
Может показаться, что в инструкциях семейства MOVA режим с автоувеличением будет применяться редко. Однако одним из примеров такого применения является генерация списков адресов для подпрограмм. Это будет рассмотрено в гл. 9.
АДРЕСАЦИЯ С АВТОУМЕНЬШЕНИЕМ
Часто бывает необходимо получать доступ к элементам массива в порядке, обратном их расположению. Для этого в архитектуре ЭВМ семейства VAX предусмотрен ещё одни режим адресации, который называется режимом с автоуменьшением. Режим с автоуменьшением по сути то же самое, что и режим с автоувеличением: адрес содержащийся в регистре общего назначения уменьшается на четыре, два или единицу при адресации длинных слов, слов или байтов соответственно. Другое отличие вытекает из необходимости симметрии между этими двумя режимами. В режиме с автоувеличением адрес в регистре общего назначения увеличивается после его использования. В режиме с автоуменьшением адрес в регистре уменьшается перед его использованием. Это означает, что инструкция с автоуменьшением выполняет противоположную адресную операцию по отношению к инструкции с автоувеличением. Данное свойство очень важно для реализации стека. Как уже говорилось в гл. 5, аналогией стека является стопка тарелок, в которой удаляемая тарелка - это самая последняя из добавленных в стопку. (Если тарелки добавляются и убираются с верхушки стопки, то верхняя тарелка - всегда последняя из добавленных.) Как будет показано в гл. 9, существующая симметрия между режимами с автоувеличением и автоуменьшением позволяет программистам легко реализовать стек.
В языке ассемблера режим с автоуменьшением обозначается следующим образом:
CLRL -(R3)
При выполнении инструкции значение в регистре R3 уменьшается на четыре, а затем ячейка, адрес которой содержится в R3, очищается. Обратите внимание на то, что знак "минус" должен стоять перед операндом, в отличие от режима с автоувеличением, в котором знак "плюс" стоит после операнда. Это должно напоминать программисту, что уменьшение адреса производится до его использования, а увеличение - после. Действие предыдущей инструкции даёт тот же результат, что и две следующие инструкции:
SUBL2 #4,R3 CLRL (R3)
В качестве примера применения режима с автоуменьшением рассмотрим программу на рис. 7.6, в которой осуществляется пересылка массива A, состоящего из 20 длинных слов, в массив B с изменением порядка следования элементов (длинных слов) на обратный. Обратите внимание, что в инструкции MOVAL #B+BYTES,R1 в регистр R1 загружается адрес длинного слова, следующего за последним длинным словом массива B. (Если 20 длинных слов массива имеют адреса ^X0400, ^X0404, ^X0408, ... , ^X044C, то адрес, загруженный в регистр R1, равен ^X0400 плюс константа BYTES. Поскольку BYTES равна 20, умноженному на 4, т.е. 80 десятичное или ^X50, то в регистр R1 загружается адрес ^X0400 плюс ^X50 или ^X0450. Однако поскольку в инструкции MOVL используется режим с автоуменьшением, то значение в регистре R1 уменьшается до ^X00000450 минус ^X4 или ^X0000044C перед тем, как будет осуществлена первая пересылка элемента в массив B.
SIZE=20 ; МАССИВ СОДЕРЖИТ 20 ДЛИННЫХ СЛОВ BYTES=SIZE*4 ; КОТОРЫЕ ЗАНИМАЮТ 80 БАЙТОВ A: .BLKL SIZE B: .BLKL SIZE . . . REVERSE: MOVAL A,R0 ; УКАЗАТЕЛЬ НАЧАЛА МАССИВА A MOVAL B+BYTES,R1 ; УКАЗАТЕЛЬ КОНЦА МАССИВА В CLRL R2 ; СЧЁТЧИК ЦИКЛА (ОТ 0 ДО SIZE-1) 10$: MOVL (R0)+,-(R1) AOBLSS #SIZE,R2,10$
Рис. 7.6. Программа переупорядочения элементов массива
РЕЖИМЫ АДРЕСАЦИИ СО СМЕЩЕНИЕМ
На рис. 7.7 приведён пример программы, в которой каждый элемент массива (кроме последнего) устанавливается равным следующему по порядку элементу. Эта операция соответствует удалению из массива первого элемента.
На рис. 7.8,а показано, как эта программа может быть реализована на языке ассемблера с применением адресации в режиме с автоуменьшением. Обратите внимание, что используется три регистра. Регистр R0 содержит адрес элемента A[I], регистр R1 содержит адрес элемента A[I+1], а регистр R2 используется как счётчик цикла, значение которого изменяется от нуля до VSIZE-1. Отметим, что VSIZE - адрес длинного слова - является переменным значением, а не константой, так что для завершения цикла используется инструкция AOBLSS VSIZE,R2,10$, а не инструкция AOBLSS #VSIZE,R2,10$. Поскольку значения в регистрах R0 и R1 увеличиваются согласованно, с разницей на четыре, то эта разница сохраняется на каждом шаге цикла.
Чтобы избежать использования двух или большего числа регистров в таких случаях, ЭВМ семейства VAX имеют набор режимов адресации со смещением. В режимах адресации со смещением учитывается фиксированное смещение относительно адреса, содержащегося в регистре. В языке ассемблера операнд, адресуемый в таком режиме, обозначается как некоторое число (или символическое имя, определяющее число), за которым следует имя регистра, заключённое в скобки. Например, по инструкции CLRL 16(R4) выполняется очистка содержимого длинного слова, смещённого на 16 байтов относительно адреса, содержащегося в R4. Если регистр R4 содержит ^X000003A4, то будет очищено содержимое длинного слова по адресу ^X000003B4.
На рис. 7.8,б показано, как ассемблерная программа рис. 7.8, может быть написана с использованием режима адресации со смещением, что позволяет уменьшать число используемых регистров. Одним из источников смущения в такой программе является инструкция MOVL 4(R0),(R0)+, в которой используется регистр R0 в двух операндах (один из которых адресуется в режиме с автоувеличением). Смещение вызывается тогда, когда точно происходит увеличение содержимого регистра R0. Основное правило состоит в том, что операнды инструкции обрабатываются один за другим в том порядке, в каком они указаны в ней. Следовательно, хотя автоувеличение выполняется для второго операнда, оно не влияет на вычисление исполнительного адреса первого операнда.
| Паскаль | Фортран |
|---|---|
FOR I := 1,VSIZE-1 |
DO I=1,VSIZE-1 |
Рис. 7.7. Программа пересылки данных в массиве
| (а) Вариант с использованием режима с автоувеличением |
(б) Вариант с использованием режима со смещением |
|---|---|
MOVAL A,R0 MOVAL A+4,R1 CLRL R2 SUBL3 #1,VSIZE,R3 10$: MOVL (R1)+,(R0)+ AOBLSS R3,R2,10$ |
MOVAL A,R0 CLRL R2 SUBL3 #1,VSIZE,R3 10$: MOVL 4(R0),(R0)+ AOBLSS R3,R2,10$ |
Рис. 7.8. Использование режима адресации со смещением
Следующий пример представляет несколько причудливый вариант программы рис. 7.8,б, в котором для адресации первого операнда используется режим с автоувеличением:
MOVAL A+4,R0 CLRL R2 SUBL3 #1,VSIZE,R3 10$: MOVL (R0)+,-8(R0) AOBLSS R3,R2,10$
Обратите внимание, что для второго операнда должен указываться адрес, на четыре меньший чем адрес первого операнда. Так как содержимое регистра R0 будет уже увеличено на четыре, смещение адреса для второго операнда должно быть -8. Этот пример показывает, что смещение представляет собой число в дополнительном коде и может быть отрицательным.
Для экономии памяти предусмотрены три режима адресации со смещением. В первом смещение задаётся в формате байта, в диапазоне значений -128...+127. Во втором - смещение задаётся в формате слова в диапазоне -32768...+32767. В третьем режиме смещение указывается в формате длинного слова и может адресовать любую ячейку памяти.
Если значение смещения достаточно мало и может поместиться в формате байта (т.е находиться в диапазоне -128 ... +127), то ассемблер для указания такого смещения выберет формат байта. Если значение смещения выходит за границы этого диапазона, то для задания смещения будет выбран формат слова или длинного слова. Если неизвестно точно значение смещения, ассемблер будет использовать для задания смещения формат длинного слова. (Это может произойти, если символические имя определяется в программе позже.) Можно отменить автоматический выбор формата смещения, если перед полем адреса поместить служебный символ, а именно
B^ |
Смещение, заданное в формате байта |
W^ |
Смещение, заданное в формате слова |
L^ |
Смещение, заданное в формате длинного слова |
Например, инструкция
CLRL W^X(R3)
будет ассемблироваться со смещением, заданным в формате слова, независимо от того, помещается ли значение X в формате слова. Обычно это приводит к ошибкам, если формат для смещения выбран неправильно. Поэтому широкое использование приведённых выше служебных символов не рекомендуется.
В последнем примере адрес A+4 помещается в регистр R0 с помощью инструкции MOVAL A+4,R0. Это сделано для того, чтобы избежать искушения объединить два режима: режим со смещением и режим с автоувеличением - в одном спецификаторе операнда типа 4(R0)+. В ЭВМ семейства VAX такого режима адресации нет и операнд, подобный 4(R0)+ вызовет ошибку ассемблирования. Такие выражения, как A+4, и режимы типа -8(R0) могут показаться сложными; на самом деле в последней приведённой программе выполняется то же самое, что и в программе рис. 7.8,б. Отметим, что выражения типа A+4 вычисляются в процессе ассемблирования и не требуют времени при выполнении программы.
ИНДЕКСНЫЙ РЕЖИМ АДРЕСАЦИИ
Хотя режимы со смещением, регистровый, косвенный, с автоувеличением и автоуменьшением обеспечивают богатый выбор способов обработки массивов, каждый из них имеет свои недостатки. Регистровый косвенный режим, режимы с автоувеличением и автоуменьшением удобны для последовательной выборки элементов одного массива. Однако эти режимы неудобны для произвольной выборки элементов массива и ещё более неудобны для связанной обработки нескольких массивов. Например, при реализации на языке ассемблера с использованием регистрового косвенного режима адресации следующих аналогичных программ на языках Паскаль и Фортран:
| Паскаль | Фортран |
|---|---|
I := ПРОИЗВОЛЬНОЕ ЗНАЧЕНИЕ; |
I = ПРОИЗВОЛЬНОЕ ЗНАЧЕНИЕ |
потребовалось бы отдельно вычислить адреса A(I), B(I), C(I) и поместить их в три разных регистра, чтобы можно было выполнить инструкцию
ADDL3 (R2),(R3),(R1)
Заметим, что значение I должно быть умножено на четыре, если A, B и C описаны как массивы типа INTEGER. В результате эквивалентная ассемблерная программа будет иметь следующий вид:
MULL3 I,#4,R4 ; СМЕЩЕНИЕ (БАЙТ) ПОМЕСТИТЬ В R4 MOVAL A-4,R1 ; АДРЕС А[I] ПОМЕСТИТЬ В R1 ADDL2 R4,R1 MOVAL B-4,R2 ; АДРЕС В[I] ПОМЕСТИТЬ В R2 ADDL2 R4,R2 MOVAL C-4,R3 ; АДРЕС А[I] ПОМЕСТИТЬ В R3 ADDL2 R4,R3 ADDL3 (R2),(R3),(R1) ;А[I]:=В[I]+С[I]
В инструкциях MOVAL от значения символических адресов A, B, C отнимается четыре. Это следствие того, что и в Паскале, и в Фортране индекс младшего элемента массива обычно равен 1. Поэтому в программе на языке ассемблера символическое имя A определяет адрес элемента A[1] или A(1). Если индекс I равен 1, то по инструкции MULL3 вычисляется смещение I*4 или ^X00000004 и помещается в регистр R4, а затем с помощью трёх инструкций ADDL2 формируются в регистрах R1, R2 и R3 адреса элементов в массивах A, B и C соответственно. Адрес A-4 называется базовым адресом массива A, так как для получения адреса конкретного элемента массива значение этого адреса складывается со значением смещения. Аналогично адреса B-4 и C-4 являются базовыми для массивов B и C.
Инициализация трёх отдельных регистров требует больших затрат времени и памяти. Ясно, что режимы с автоувеличением и с автоуменьшением не помогут в решении этой проблемы, если на последующих шагах программы не будет выполняться последовательное сканирование массивов A, B и C. Эту задачу можно решить при использовании ещё одного режима адресации, называемого индексным. Программу можно переписать следующим образом, применяя индексный режим адресации:
MOVL I,R0 ADDL3 B-4[R0],C-4[R0],A-4[R0]
Обратите внимание, что форма записи для обозначения индексного режима похожа на запись, применяемую в языках высокого уровня. В инструкции ADDL3 обозначение каждого операнда состоит из базового адреса, такого как B-4 или C-4, за которым следует имя регистра, заключённое в квадратные скобки, например [R0].
Исполнительный адрес вычисляется так: к смещению, равному умноженному на четыре значению, содержащемуся в индексном регистре (в данном случае - в регистре R0) , прибавляется значение базового адреса. Поэтому в программе нет необходимости умножать I на четыре. Обратите внимание, что содержимое регистра R0 умножается на четыре, потому что инструкция ADDL3 работает с длинными словами. Если индексный режим используется для адресации операндов, имеющих формат байтов или слов, происходит автоматическое умножение на один или два, а если операнд - квадраслово, то происходит умножение на восемь.
В отличие от остальных режимов адресации, индексный режим всегда используется в сочетании с одним из других режимов. Другие режимы используются для вычисления базового адреса, к которому прибавляется смещение, вычисляемое в зависимости от указываемого индекса. В этом случае используется одна из форм относительной адресации для получения базовых адресов A-4, B-4 и C-4. В результате инструкция ADDL3 становится позиционно независимой. Более того, если массивы A, B и C размещены в памяти достаточно близко к инструкции ADDL3, то ассемблер для A-4, B-4 и C-4 будет использовать относительную адресацию со смещением, заданным в формате байта или слова. В результате инструкция может занимать 10-13 байтов.
Как ранее говорилось, индексный режим используется в сочетании с другими режимами. Например, можно написать такую инструкцию, как
CLRL (R2)+[R0]
При этом исполнительный адрес вычисляется так: значение в регистре R0, умноженное на четыре, складывается со значением адреса в регистре R2, после чего производится очистка ячейки, расположенной по вычисленному адресу. Затем адрес в регистре R2 увеличивается на четыре.
На рис. 7.9 показано, как может быть переписана программа рис. 7.5 с использованием индексного режима адресации. Как видно из рис. 7.9, нет особой разницы между двумя вариантами программы, за исключением того, что в программе, в которой используется индексный регистр, значение в регистре R0 увеличивается на единицу, а не на четыре. Однако последний вариант концептуально проще, поскольку регистр R0 содержит индекс, а не адрес.
| (а) Вариант с регистровой косвенной адресацией |
(б) Вариант с использованием индексной адресации |
|---|---|
SIZE=20 SUM: .BLKL 1 DATA: .BLKL SIZE . . . ADDUP: MOVAL DATA,R0 CLRL R1 CLRL SUM 10$: ADDL2 (R0),SUM ADDL2 #4,R0 AOBLSS #SIZE,R1,10$ |
SIZE=20 SUM: .BLKL 1 DATA: .BLKL SIZE . . . ADDUP: CLRL R0 CLRL R1 CLRL SUM 10$: ADDL2 DATA[R0],SUM INCL R0 AOBLSS #SIZE,R1,10$ |
Рис. 7.9. Суммирование 20 чисел с использованием индексного режима адресации.
Другое преимущество индексного режима может быть обнаружено, если проследить за изменением содержимого регистров R0 и R1. В программе рис. 7.9,а регистр R0 содержит адрес, а регистр R1 используется как счётчик цикла. Во втором примере (рис. 7.9,б), регистр R0 содержит индекс, а регистр R1 опять используется как счётчик цикла. При детальном рассмотрении второго варианта программы выясняется, что регистры R0 и R1 содержат одинаковое значение. Содержимое обоих регистров сбрасывается в 0 перед началом цикла и увеличивается на 1 при каждом проходе цикла. Поскольку регистры содержат одно и то же значение, то один из них оказывается лишним и программа может быть переписана следующим образом:
ADDUP: CLRL R0 CLRL SUM 10$: ADDL2 DATA[R0],SUM AOBLSS #SIZE,R0,10$
7.4. РЕЖИМЫ АДРЕСАЦИИ С ИСПОЛЬЗОВАНИЕМ РЕГИСТРОВ
ОБЩЕГО НАЗНАЧЕНИЯ
ОБЗОР
В табл. 7.1 приведены режимы адресации, описанные в данной главе. (Обратите внимание, что регистровый режим адресации также включен в таблицу.) Все эти режимы относятся к режимам адресации с использованием регистров общего назначения (за исключением программного счётчика - регистра R15). Слева в таблице перечислены названия режимов. Справа на примере инструкции CLRL с использованием регистра общего назначения R3 показано обозначение этих режимов в языке ассемблера.
Для интерпретации содержимого средней колонки табл. 7.1 вспомним, что каждая инструкция в машинном коде состоит из числового кода операции, за которым следует соответствующее число спецификаторов операндов. Каждый спецификатор операнда состоит из байта спецификатора операнда, который может сопровождать дополнительная информация, такая как смещение, зависящая от значения байта спецификатора операнда. Байт спецификатора операнда представляется двумя шестнадцатеричными цифрами. Вторая шестнадцатеричная цифра задаёт номер регистра общего назначения, используемого при определении адреса операнда. Первая шестнадцатеричная цифра в байте спецификатора операнда задаёт код режима адресации, указывающий, как этот регистр будет использоваться при определении адреса операнда.
| Режим адресации |
Байт спецификатора |
Код операции |
Пример на языке |
||
|---|---|---|---|---|---|
Регистровый |
|
53 |
D4 |
CLRL |
R3 |
Регистровый косвенный |
|
63 |
D4 |
CLRL |
(R3) |
С автоуменьшением |
|
73 |
D4 |
CLRL |
- (R3) |
С автоувеличением |
|
83 |
D4 |
CLRL |
(R3)+ |
Со смещением (байт) |
xx |
A3 |
D4 |
CLRL |
D(R3) |
Со смещением (слово) |
xxxx |
C3 |
D4 |
CLRL |
D(R3) |
Со смещением (длинное слово) |
xxxxxxxx |
E3 |
D4 |
CLRL |
D(R3) |
Относительный индексный (смещение - байт) |
xx |
AF 43 |
D4 |
CLRL |
A[R3] |
Относительный индексный (смещение - слово) |
xxxx |
CF 43 |
D4 |
CLRL |
A[R3] |
Относительный индексный (смещение - длинное слово) |
xxxxxxxx |
EF 43 |
D4 |
CLRL |
A[R3] |
Примечание. Символ A обозначает адрес, символ D обозначает смещение. Формат смещения - байт, слово или длинное слово выбирается ассемблером в зависимости от значения смещения. |
|||||
В средней колонке табл. 7.1 в поле кода операции помещается код операции ^XD4, соответствующий инструкции CLRL. Слева от него под заголовком "Спецификатор операнда" расположен байт спецификатора операнда. Во всех примерах второй цифрой байта спецификатора операнда является ^X3, так как используется регистр общего назначения R3. Первая цифра определяет код режима адресации. Как видно из таблицы, код ^X5 обозначает режим регистровой адресации, код ^X6 задаёт режим регистровой косвенной адресации и т.д.
Заметим, что регистровый косвенный режим, режимы с автоувеличением и автоуменьшением (код режима ^X6, ^X7 и ^X8 соответственно) весьма схожи между собой в том, что в регистре содержится адрес операнда. В регистровом косвенном режиме содержимое регистра не меняется. В режиме с автоуменьшением адрес в регистре уменьшается перед его использованием, в режиме с автоувеличением адрес в регистре увеличивается после его использования.
Коды ^XA, ^XC и ^XE обозначают режимы адресации со смещением, заданным соответственно в формате байта, слова и длинного слова. Ассемблер формирует байт, слово или длинное слово смещения и располагает его в памяти непосредственно за байтом спецификатора операнда. В табл. 7.1 значение смещения обозначено символами xx, xxxx и xxxxxxxx.
Напомним, что во время выполнения инструкции программный счётчик указывает на разные байты этой инструкции. После завершения выполнения инструкции программный счётчик должен указывать на начало следующей инструкции. Чтобы обеспечить это в режимах адресации со смещением, заданным в формате байта, слова и длинного слова, к содержимому программного счётчика автоматически прибавляется 1, 2 или 4 соответственно, чтобы "пропустить" нужное количество байтов, отведённых в данной инструкции под смещение. Увеличение содержимого программного счётчика происходит автоматически, независимо от содержимого регистра общего назначения, используемого для адресации со смещением. Например, в инструкции
CLRL L^X(R3)
указан режим со смещением, заданным в формате длинного слова. При выполнении инструкции к содержимому программного счётчика будет прибавлено число 4, чтобы "пропустить" 4-байтовое смещение. В результате программный счётчик будет указывать на начальный адрес следующей инструкции. (Обратите внимание, что содержимое регистра R3 при этом не меняется.) Это увеличение не должно беспокоить программиста, поскольку во всех режимах адресации со смещением увеличение значения программного счётчика осуществляется автоматически.
В последних трёх строчках табл. 7.1 приведены примеры индексной адресации (режим 4). В отличие от остальных режимов режим индексной адресации должен использоваться в сочетании с некоторым другим режимом адресации. Использование в инструкциях только индексной адресации недопустимо, например нотация CLRL [R3] является неправильной. В режиме индексной адресации регистр содержит значение индекса, которое используется для вычисления смещения. Второй режим адресации, в сочетании с которым используется индексная адресация, обеспечивает формирование адреса, с которым складывается значение смещения. Регистровый, литеральный и непосредственный режимы адресации не могут использоваться в сочетании с индексной адресацией, поскольку они не формируют адрес операнда, к которому можно было бы прибавить значение смещения.
В табл. 7.1 индексная адресация используется в сочетании с относительной адресацией[1]. Байт спецификатора операнда индексного режима с регистром R3 в качестве индексного регистра содержит код ^X43. Непосредственно за ним следует байт спецификатора операнда для относительной адресации со смещением, заданным в формате байта, слова или длинного слова (коды ^XAF, ^XCF или ^XEF соответственно). Режимы относительной адресации указывают базовый адрес массива, а режим индексной адресации указывает индекс требуемого элемента в массиве.
ЛИТЕРАЛЬНЫЙ РЕЖИМ АДРЕСАЦИИ
В табл. 7.1 приведены восемь режимов адресации, имеющие коды режима 4, 5, 6, 7, 8, А, С и Е. Очевидно, что незадействованные коды можно использовать для других целей. Как уже говорилось в гл. 5, байт спецификатора операнда, имеющий значения от ^X00 до ^X3E, используется для задания литерального режима. Отличительным признаком этого режима является то, что два старших бита в байте спецификатора операнда содержат нули. В этом случае оставшиеся шесть битов рассматриваются как заданное непосредственно 6-битовое число без знака. Это позволяет описывать в одном байте непосредственно заданные операнды, имеющие значения в диапазоне 0-63. Значение литерала должно быть положительным. Ассемблер автоматически выбирает литеральный режим для небольших по значению положительных непосредственно заданных операндов. Например, при ассемблировании следующей инструкции:
MOVL #5,R0
могут быть получены следующие три байта машинного кода:
50 05 D0
Инструкция с большими по значению непосредственно заданными операндами, такая как
MOVL #64,R0
ассемблируется с использованием режима непосредственной адресации и будет занимать 7 байтов:
50 00000040 8F D0
Поскольку литерал не имеет знака, то желательно избегать непосредственного задания небольших отрицательных операндов. Эго можно сделать, если правильно выбрать инструкцию. Например, инструкция MNEGL #5,R0 более предпочтительна, чем инструкция MOVL #-5,R0, так как в машинном коде первая инструкция будет занимать три байта, а вторая - семь байтов.
РЕЖИМЫ КОСВЕННОЙ АДРЕСАЦИИ
Как уже было показано в разд. 7.2, существует режим адресации, называемый регистровым косвенным режимом. В этом режиме содержимое регистра не используется как операнд, а рассматривается как адрес операнда. Существует ещё четыре режима косвенной адресации, которые могут использоваться в сочетании с режимом с автоувеличением и с тремя режимами адресации со смещением (все они приведены в табл. 7.2).
| Режим адресации |
Байт спецификатора |
Код операции |
Пример на языке |
|---|---|---|---|
Косвенный с автоувеличением |
93 |
D4 |
CLRL @(R3)+ |
Косвенный со смещением (байт) |
B3 |
D4 |
CLRL @D(R3) |
Косвенный со смещением (слово) |
D3 |
D4 |
CLRL @D(R3) |
Косвенный со смещением (длинное слово) |
F3 |
D4 |
CLRL @D(R3) |
Примечание. Символ D обозначает
смещение. Ассемблер автоматически в зависимости |
|||
| Режим адресации |
Байт спецификатора |
Код |
Пример на языке |
|
|---|---|---|---|---|
Литеральный |
50 |
05 |
D0 |
MOVL #5,R0* |
Индексный |
....xx |
43 |
D4** |
CLRL A[R3] |
Регистровый |
|
53 |
D4 |
CLRL R3 |
Регистровый косвенный |
|
63 |
D4 |
CLRL (R3) |
С автоуменьшением |
|
73 |
D4 |
CLRL -(R3 ) |
С автоувеличением |
|
83 |
D4 |
CLRL (R3)+ |
Косвенный с автоувеличением |
|
93 |
D4 |
CLRL @(R3)+ |
Со смещением (байт) |
xx |
А3 |
D4 |
CLRL D(R3) |
Косвенный со смещением (байт) |
xx |
В3 |
D4 |
CLRL @D(R3) |
Со смещением (слово) |
xxxx |
С3 |
D4 |
CLRL D(R3) |
Косвенный со смещением (слово) |
xxxx |
D3 |
D4 |
CLRL @D(R3) |
Со смещением (длинное слово) |
xxxxxxxx |
Е3 |
D4 |
CLRL D(R3) |
Косвенный со смещением (длинное слово) |
xxxxxxxx |
F3 |
D4 |
CLRL @D(R3) |
* Литеральный режим разрешён только для операнда-источника. Примечание. Символ D обозначает
смещение. Формат смещения - байт, слово |
||||
В каждом случае такой адресации адрес вычисляется точно так же, как это делается в случае режимов некосвенной адресации. По этому адресу выбирается длинное слово, и содержимое этого длинного слова используется как адрес операнда инструкции. В случае косвенной адресации с автоувеличением значение содержимого регистра увеличивается на четыре. Эго делается независимо от типа инструкции, потому что в регистре всегда содержится некоторый адрес, а адрес всегда занимает длинное слово. Такие режимы косвенной адресации используются в основном для работы с таблицами адресов. Адреса в таблице являются адресами операндов или более сложных структур данных.
Таблица 7.3 содержит полный список режимов адресации с использованием регистров общего назначения, реализованных в ЭВМ семейства VAX.
7.5. РЕЖИМЫ АДРЕСАЦИИ С ИСПОЛЬЗОВАНИЕМ ПРОГРАММНОГО СЧЁТЧИКА
В предыдущих главах был описан целый ряд режимов адресации, использующих программный счётчик. Эти режимы называются режимами адресации с использованием программного счётчика и перечислены в табл. 7.4. Непосредственная адресация иллюстрируется инструкцией MOVL, а для других режимов адресации в качестве примера приводится инструкция CLRL. Обратите внимание на символы @# во второй строке: они используются в инструкции CLRL @#A для указания режима абсолютной адресации, который рассматривался в гл. 3. Байты спецификатора операнда в этой таблице содержат коды ^X8F, ^X9F, ^XAF, ^XCF и ^XEF. Везде код ^XF указывает, что для определения адреса операнда используется программный счётчик. Символы х, следующие за байтом спецификатора операнда, показывают, сколько шестнадцатеричных цифр, обозначающих дополнительную информацию, должно стоять после байта спецификатора операнда.
| Режим адресации |
Байт |
Код операции |
Пример на языке |
|
|---|---|---|---|---|
Непосредственный |
50 xxxxxxxx |
8F |
D0 |
MOVL #K,R0* |
Абсолютный |
xxxxxxxx |
9F |
D4 |
CLRL @#A |
Относительный (смещение - байт) |
xx |
AF |
D4 |
CLRL A |
Относительный (смещение - слово) |
xxxx |
CF |
D4 |
CLRL A |
Относительный (смещение - длинное слово) |
xxxxxxxx |
EF |
D4 |
CLRL A |
* Непосредственная адресация разрешена только для операнда-источника. Примечание. Символ A обозначает
адрес, символ K обозначает константу. Формат
смещения - байт, |
||||
Использовать программный счётчик точно так же, как и регистры общего назначения, нежелательно, так как это может привести к непредсказуемым результатам. Однако существует множество подходящих способов его использования, показанных в табл. 7.4. В процессе декодирования инструкции процессор ЭВМ семейства VAX увеличивает значение содержимого программного счётчика на 1 каждый раз, когда происходит выборка очередного байта. Это означает, что на любом этапе декодирования инструкции программный счётчик указывает на следующий байт, выборка которого должна осуществляться. Как это происходит, можно увидеть, рассмотрев выполнение инструкции
MOVL #100,R0
В машинном коде инструкция выглядит следующим образом:
50 00000064 8F D0
Байт спецификатора операнда ^X8F указывает, что применяется режим адресации с автоувеличением с использованием регистра ^XF, т.е. программного счётчика.
Предположим, что эта инструкция размещается, начиная с адреса ^X00000300. Тогда расположение байтов в памяти будет следующим:
| Содержимое |
Адрес |
|---|---|
D0 |
0300 |
8F |
0301 |
64 |
0302 |
00 |
0303 |
00 |
0304 |
00 |
0305 |
50 |
0306 |
Перед началом выполнения инструкции в программном счётчике будет находиться адрес ^X0300. После выборки, кода операции ^XD0 значение содержимого программного счётчика увеличивается на 1 и становится равным ^X0301. Код ^XD0 опознаётся как код операции инструкции MOVL. Эта инструкция имеет два операнда. Процессор продолжит выборку первого операнда, по адресу ^X0301 выбирается байт ^X8F, после чего значение содержимого программного счётчика увеличивается на 1 и становится равным ^X0302. Выбранный байт - это байт спецификатора операнда. В байте спецификатора операнда код ^X8 обозначает режим адресации с автоувеличением, a ^XF обозначает, что используется регистр 15 (или программный счётчик). Поскольку программный счётчик содержит ^X0302, выбирается длинное слово по адресу ^X0302. Таким образом, первым операндом инструкции MOVL является значение ^X00000064. Однако, поскольку задан режим адресации с автоувеличением, значение содержимого программного счётчика увеличивается теперь на 4 и становится равным ^X0306. После этого декодирование инструкции продолжается с адреса ^X0306, по которому выбирается байт ^X50. Это - байт спецификатора второго операнда. Он указывает, что применяется регистровая адресация с использованием регистра общего назначения R0. Поэтому значение ^X00000064 пересылается в регистр R0.
Как видно из этого примера, непосредственная адресация - это просто режим адресации с автоувеличением, в котором вместо регистра общего назначения используется программный счётчик. Аналогичное исследование других режимов адресации показывает, что не во всех этих режимах можно применять программный счётчик. Например, инструкция в машинном коде
50 00000064 6F D0
отличается от только что рассмотренной тем, что в ней используется регистровая косвенная адресация (режим 6) вместо адресации с автоувеличением. Будет произведена выборка операнда ^X00000064, но содержимое программного счётчика не будет увеличено надлежащим образом, чтобы указывать на следующий байт спецификатора операнда (^X50). Адресация с автоуменьшением (режим 7) не позволит даже осуществить выборку операнда ^X00000064, потому что содержимое программного счётчика будет уменьшено до того, как будет произведена выборка операнда. По этим и другим причинам режимы адресации, имеющие код с 4-ого по 7-й, не используются с программным счётчиком.
Однако программный счётчик можно применять в режимах адресации, имеющих код с 8-ого по 15-й (с ^X8 по ^XF). Ниже показано, как реализуются эти пять режимов адресации с использованием программного счётчика (регистр PC), приведённые в табл. 7.4, с помощью режимов адресации с использованием регистров общего назначения при замене регистра общего назначения на регистр PC.
| Режим адресации с использованием регистра PC |
Реализация |
|---|---|
Непосредственный |
Режим с автоувеличением с использованием регистра PC |
Абсолютный |
Режим косвенной адресации с автоувеличением с использованием регистра PC |
Относительный (смещение - байт) |
Режим адресации со смещением, заданным в формате байта, с использованием регистра PC |
Относительный (смещение - слово) |
Режим адресации со смещением, заданным в формате слова, с использованием регистра PC |
Относительный (смещение - длинное слово) |
Режим адресации со смещением, заданным в формате длинного слова, с использованием регистра PC |
Для понимания того, как режим относительной адресации со смещением, заданным в формате байта, реализуется с помощью режима адресации со смещением, заданным в формате байта, в котором вместо регистра общего назначения используется регистр PC, предположим, что, начиная с адреса ^X0300, расположена следующая инструкция, занимающая три байта памяти:
| Содержимое |
Адрес |
|---|---|
D4 |
0300 |
AF |
0301 |
F1 |
0302 |
Когда содержимое байта по адресу ^X0300 выбирается и интерпретируется как код инструкции, обнаруживается, что это инструкция CLRL, имеющая один операнд. Байтом спецификатора операнда является байт ^XAF. Этот код указывает на использование режима адресации со смещением, заданным в формате байта, относительно регистра R15, т.е. программного счётчика. Затем выбирается байт смещения ^XF1. В дополнительном коде это значение соответствует числу -15, которое надо прибавить к содержимому программного счётчика, чтобы получить исполнительный адрес. Поскольку содержимое программного счётчика увеличивалось при выборке каждого байта, то в настоящий момент он содержит адрес ^X0303, т.е. на единицу больше адреса байта смещения, выбранного последним[2]. Следовательно, исполнительный адрес вычисляется сложением ^XF1 (с распространённым знаковым разрядом) и ^X0303, что даёт в результате
^X00000303 +^XFFFFFFF1 ^X000002F4
Таким образом общается содержимое длинного слова, расположенного по адресу ^X02F4. Это обычная схема адресации при выполнении инструкции
CLRL A
Относительная адресация со смещением, заданным в формате слова и длинного слова, выполняется аналогично. Ассемблер обычно автоматически выбирает наилучший вариант относительной адресации, если значение адреса известно. Если же адрес неизвестен, то ассемблер использует на всякий случай смещение, заданное в формате длинного слова. Возможны две причины, по которым ассемблер может не знать адрес. Первая связана с настройкой адресов, описанной в гл. 9. Вторая заключается в том, что символическое имя, используемое для задания адреса, или в адресном выражении, не было пока ещё определено в программе. По этой причине обычно рекомендуется описывать все области данных в начале программы. Это поможет сократить число ссылок вперёд, которые приводят к чрезмерному использованию смещений, задаваемых в формате длинного слова.
В режимах косвенной адресации со смещением также можно использовать программный счётчик. В этих случаях содержимое адресуемого длинного слова будет рассматриваться как адрес, а не как операнд. В следующей инструкции применяется режим косвенной адресации со смещением
CLRL @A
В данном случае очищается не длинное слово с адресом A, а ячейка, адрес которой содержится в длинном слове с адресом A.
В табл. 7.5 приводится полный список режимов адресации с использованием программного счётчика, реализованных на ЭВМ семейства VAX.
| Режим адресации |
Байт спецификатора |
Код операции |
Пример на языке |
|
|---|---|---|---|---|
Непосредственный |
50 xxxxxxxx |
8F |
D0 |
MOVL #K,R0* |
Абсолютный |
xxxxxxxx |
9F |
D4 |
CLRL @#A |
Относительный (смещение- байт) |
xx |
AF |
D4 |
CLRL A |
Относительный косвенный (смещение - байт) |
xx |
BF |
D4 |
CLRL @A |
Относительный (смещение - слово) |
xxxx |
CF |
D4 |
CLRL A |
Относительный косвенный (смещение - слово) |
xxxx |
DF |
D4 |
CLRL @A |
Относительный (смещение - длинное слово) |
xxxxxxxx |
EF |
D4 |
CLRL A |
Относительный косвенный (смещение - байт) |
xxxxxxxx |
FF |
D4 |
CLRL @A |
* Непосредственная адресация разрешена только для операнда-источника. Примечание. Символ A обозначает
адрес, символ K - число. Формат смещения
- байт, слово, |
||||
7.6. МНОГОМЕРНЫЕ МАССИВЫ
РАЗМЕЩЕНИЕ МАССИВОВ В ПАМЯТИ
Практика работы с языками Паскаль и Фортран показывает, что часто требуются многомерные массивы. Наиболее часто массивы представляются в виде матрицы (см. рис. 7.10).
Поскольку память ЭВМ имеет линейную организацию, более сложные структуры данных, такие как матрицы, должны быть отображены или преобразованы в линейный формат. Для матриц и подобным им структур данных это обычно делается разбиением матрицы на некоторое число одномерных массивов или строк[3]. Матрицу можно развернуть либо по строкам - расположив в памяти строки подряд одну за другой, либо по столбцам - расположив подряд столбцы. В принципе эти два варианта мало чем отличаются.
Большинство компиляторов Фортрана размещают в памяти матрицы по столбцам. Компилятор Паскаля для ЭВМ семейства VAX размещает матрицы по строкам. В табл. 7.6 показано, как матрица размером 5x7, элементами которой являются целые числа в формате длинного слова, размещается в памяти ЭВМ семейства VAX, начиная с адреса ^X00003C00, согласно правилам, принятым для языка Фортран. Для языка Паскаль такое размещение в памяти будет соответствовать матрице размера 7x5 и другому порядку индексов, т.е. элемент A(I,J) в Фортране становится элементом A[J,I] в Паскале. Применительно к Паскалю в приведённых ниже пояснениях следует взаимозаменить понятия "строка" и "столбец".
A11 |
A12 |
A13 |
... |
A1n |
A21 |
A22 |
A23 |
... |
A2n |
A31 |
A32 |
A33 |
... |
A3n |
. |
. |
. |
|
. |
. |
. |
. |
... |
. |
. |
. |
. |
|
. |
Am1 |
Am2 |
Am3 |
... |
Amn |
Рис. 7.10. Матрица размера m x n
| Адрес |
Элемент матрицы |
Адрес |
Элемент матрицы |
Адрес |
Элемент матрицы |
|---|---|---|---|---|---|
^X00003C00 |
A11 |
^X00003C30 |
А33 |
^X00003C60 |
А55 |
^X00003C04 |
A21 |
^X00003C34 |
A43 |
^X00003C64 |
А16 |
^X00003C08 |
A31 |
^X00003C38 |
А53 |
^X00003C68 |
А26 |
^X00003C0C |
А41 |
^X00003C3C |
А14 |
^X00003C6C |
А36 |
^X00003C10 |
А51 |
^X00003C40 |
А24 |
^X00003C70 |
А46 |
^X00003C14 |
A12 |
^X00003C44 |
А34 |
^X00003C74 |
А56 |
^X00003C18 |
A22 |
^X00003C48 |
А44 |
^X00003C78 |
А17 |
^X00003C1C |
А32 |
^X00003C4C |
А54 |
^X00003C7C |
A27 |
^X00003C20 |
A42 |
^X00003C50 |
А15 |
^X00003C80 |
А37 |
^X00003C24 |
A52 |
^X00003C54 |
А25 |
^X00003C84 |
А47 |
^X00003C28 |
A13 |
^X00003C58 |
А35 |
^X00003C88 |
А57 |
^X00003C2C |
А23 |
^X00003C5C |
А45 |
|
|
Из табл. 7.6 видно, что адрес любого элемента матрицы Аi,j может быть определён при сложении соответствующего смещения элемента с базовым адресом ^X00003C00. Смещение вычисляется по формуле 4[i-1+5(j-1)]. Например, если требуется выбрать элемент матрицы А36, то i = 3 и j = 6 и смещение для этого элемента
4[3 - 1 + 5(6 - 1)] = 10810 = ^X6C.
В результате получается адрес ^X00003C6C. Рассмотрим, как найдена эта формула. Матрица размещена в памяти так, что первый столбец занимает первые пять длинных слов памяти, второй занимает следующие пять длинных слов и т.д. Таким образом начало j-ого столбца смещено на 5 (j-1) длинных слов от начала массива. От начала этого столбца i-е длинное слово в столбце смещено на i-1 длинных слов или на i-1+5(j-1) длинных слов от начала массива. (Очевидно, что первый элемент столбца имеет нулевое смещение от начала этого столбца.) Умножение на четыре требуется потому, что адреса длинных слов меняются с дискретностью четыре.
ОБРАБОТКА МАССИВОВ В ЭВМ СЕМЕЙСТВА VAX
Массивы чаще всего обрабатываются по строкам, столбцам или по диагонали. В этих случаях зачастую можно обойтись без значительных адресных вычислений. Ясно, что если матрица сканируется по столбцам, то это то же самое, что сканирование вектора из 35 элементов в случае матрицы 5x7. Поэтому можно применять многие методы, описанные в предыдущих разделах.
Довольно часто (и это отличает матрицы от одномерных массивов) при сканировании матрицы по столбцам необходимо выполнять специальные операции в конце каждого столбца. Например, можно было бы найти сумму всех чисел каждого столбца. Это легко может быть сделано, если ввести второй счётчик для проверки конца столбца. На рис. 7.11 показана программа просмотра по столбцам матрицы размером 5x7.
Как можно видеть в строчке программы с меткой 20$, для выборки элементов матрицы в программе используется индексный режим адресации. Поскольку в этом режиме индекс автоматически умножается на длину операнда, данная программа может использоваться не только для массивов с элементами, имеющими формат длинного слова, но и для массивов с элементами другого формата - байтов, слов и квадраслов. Это справедливо для всех примеров данного раздела.
На первый взгляд сканирование матрицы по строкам может показаться более сложным, чем по столбцам. Однако это ничуть не сложнее, а при использовании некоторых приёмов - даже проще. Сканирование строки означает просто увеличение адреса на соответствующее число. Обратившись к табл. 7.6, можно увидеть, что элементы А11, А12, А13, А14 и т.д. расположены по адресам ^X00003C00, ^X00003C14, ^X00003C28, ^X00003C3C и т.д. Разница между соседними адресами составляет 2010, или ^X14. (Число ^X14 соответствует десятичному 20 или числу 4, умноженному на число строк в матрице, что равно числу байтов в столбце. Напомним, что длинное слово содержит четыре байта.)
ROWS=5 COLS=7 SIZE=ROWS*COLS . . . CLRL R1 ; ИНДЕКСНЫЙ РЕГИСТР 10$: ОБРАБОТКА НАЧАЛА СТОЛБЦА . . . CLRL R2 ; РЕГИСТР СЧЁТЧИК 20$: ОБРАБОТКА ЭЛЕМЕНТА МАССИВА A[R1] . . . INCL R1 ; УВЕЛИЧЕНИЕ ИНДЕКСА AOBLSS #ROWS,R2,20$ ; КОНЕЦ СТРОКИ? ЗАВЕРШЕНИЕ ОБРАБОТКИ СТОЛБЦА . . . CMPL R1,#SIZE BLSS 10$
Рис. 7.11. Программа сканирования матрицы размера 5x7
по столбцам
ROWS=5 COLS=7 SIZE=ROWS*COLS . . . CLRL R2 ; ИНИЦИАЛИЗАЦИЯ ВСПОМОГАТЕЛЬНОГО ИНДЕКСА 10$: НАЧАЛО ОБРАБОТКИ СТРОКИ . . . MOVL R2,R1 ; ИНИЦИАЛИЗАЦИЯ ОСНОВНОГО ИНДЕКСА 20$: ОБРАБОТКА ЭЛЕМЕНТА МАТРИЦЫ A[R1] . . . ADDL2 #ROWS,R1 ; ПРИБАВИТЬ 5 ДЛЯ ПЕРЕХОДА К СЛЕДУЮЩЕМУ CMPL R1,#SIZE ; ЭЛЕМЕНТУ СТРОКИ И ПРОВЕРИТЬ BLSS 20$ ; НЕ ДОСТИГНУТ ЛИ КОНЕЦ СТРОКИ ЗАВЕРШЕНИЕ ОБРАБОТКИ СТРОКИ . . . AOBLSS #ROWS,R2,10$ ; УВЕЛИЧИТЬ ВСПОМОГАТЕЛЬНЫЙ ИНДЕКС
Рис. 7.12. Программа сканировании матрицы размера 5x7 по строкам
ROWS=5 COLS=7 SIZE=ROWS*COLS . . . CLRL R1 ; ИНДЕКСНЫЙ РЕГИСТР 10$: НАЧАЛО ОБРАБОТКИ СТРОКИ . . . 20$: ОБРАБОТКА ЭЛЕМЕНТА МАТРИЦЫ A[R1] . . . ADDL2 #ROWS,R1 ; ПРИБАВИТЬ 5 ДЛЯ ПЕРЕХОДА К СЛЕДУЮЩЕМУ CMPL R1,#SIZE ; ЭЛЕМЕНТУ СТРОКИ И ПРОВЕРИТЬ BLSS 20$ ; НЕ ДОСТИГНУТ ЛИ КОНЕЦ СТРОКИ ЗАВЕРШЕНИЕ ОБРАБОТКИ СТРОКИ . . . SUBL2 #SIZE-1,R1 ; КОНЕЦ СТРОКИ, ВЫЧЕСТЬ 34 CMPL R1,#ROWS ; ИЗ ЗНАЧЕНИЯ ИНДЕКСА И ПРОВЕРИТЬ BLSS 10$ ; ВСЕ ЛИ СТРОКИ ОБРАБОТАНЫ
Рис. 7.13. Усовершенствованная программа сканирования матрицы размера 5x7 по строкам
Поскольку в режиме индексной адресации индекс будет автоматически умножаться на 4, необходимо только позаботиться о том, чтобы каждый раз перед этим содержимое индексного регистра увеличивалось на 5. Проблема заключается в том, как инициализировать регистр-указатель в начале каждой строки. Один из способов заключается в том, чтобы иметь вспомогательный регистр-счётчик индекса, с помощью которого будет осуществляться сканирование первого столбца. На рис. 7.12 приведён пример такого подхода.
Однако существует простой арифметический приём, который делает ненужным вспомогательный счётчик. Этот приём показан на рис. 7.13. Первая строка матрицы обрабатывается при последовательном прибавлении числа 5 к значению индекса в регистре R1. Поскольку матрица размера 5x7 состоит из 35 элементов, то в результате значение в регистре станет равно 35. Когда значение в регистре R1 станет равным 35, это будет означать, что первая строка просмотрена. Если теперь вычесть из этого значения число 34, в регистре R1 окажется 1, т.е. индекс первого элемента второй строки.
ИНСТРУКЦИЯ INDEX
Для упрощения доступа к элементам двумерных массивов в ЭВМ VAX имеется сложная инструкция INDEX. Эта инструкция не только помогает в вычислении формулы индексации [i-1+5(j-1)], но также задаёт различные начальные значения индексов и проверяет, находятся ли значения индексов в диапазоне, допустимом для данного массива. Инструкцию можно использовать для работы с многомерными массивами любого размера. Инструкция INDEX имеет шесть операндов - длинных слов.
INDEX SUB,LOW,HIGH,SIZE,IXIN,IXOUT
При выполнении инструкций производится вычисление
IXOUT := (IXIN+SUB) * SIZE
и происходит прерывание по ошибке, если
SUB < LOW или SUB > HIGH
ROWS=5 COLS=7 . . . CLRL R1 ; НОМЕР СТРОКИ (ОТ 0 ДО ROWS-1) 10$: CLRL R2 ; НОМЕР СТОЛБЦА (ОТ 0 ДО COLS-1) 20$: INDEX R2,#0,#COLS-1,#ROWS,#0,R0 ; R0:=R2*ROWS INDEX R1,#0,#ROWS-1,#1,R0,R0 ; R0:=(R0+R1)*1 РАБОТА С ЭЛЕМЕНТОМ МАТРИЦЫ A[R1] . . . AOBLSS #COLS,R2,20$ AOBLSS #ROWS,R1,10$
Рис. 7.14. Использование инструкции INDEX для сканирования матрицы размера 5x7 по строкам
На рис. 7.14 показано, как программа на рис. 7.13 должна быть переписана с использованием инструкции INDEX. Для сканирования массива по столбцам, а не по строкам необходимо поменять между собой начальные значения содержимого регистров R1 и R2 и значения приращения адреса.
Преимущество инструкции INDEX заключается в том, что она может использоваться для доступа к элементам матрицы в произвольном порядке. Если регистр R1 содержит индекс строки I, изменяющийся от 0 до ROWS-1, а регистр R2 содержит индекс столбца J, изменяющийся от 0 до COLS-1, то для выборки элемента A[I,J] или A(I,J) могут использоваться следующие две инструкции:
20$: INDEX R2,#0,#COLS-1,#ROWS,#0,R0 ; R0:=R2*ROWS INDEX R1,#0,#ROWS-1,#1,R0,R0 ; R0:=(R0+R1)*1 ОБРАБОТКА ЭЛЕМЕНТА МАТРИЦЫ A[R1]
УПРАЖНЕНИЯ 7.2
- Пусть регистр R0 содержит число ^X00001200,
а в памяти размещена следующая информация:
Содержимое Адрес ^X0000120C
^X000011F4
^X000011F8
^X000011F8
^X000011F4
^X000011FC
^X0000120C
^X00001200
^X00001208
^X00001204
^X00001200
^X00001208
^X000011F4
^X0000120C
Как изменится содержимое памяти и регистра R0 после выполнения каждой из следующих инструкций? (Предполагается, что указанное состояние памяти является начальным для каждой инструкции)
а. CLRL
R0
б. CLRL
(R0)
в. CLRL
(R0)+
г. CLRL
-(R0)
д. MOVL
R0,(R0)
е. MOVL
(R0),R0
ж. MOVL
(R0)+,(R0)+
3. MOVL
(R0)+,(R0)
и. MOVL
(R0)+,-(R0)
к. MOVL
-(R0),-(R0)
л. MOVL
@(R0)+,R0
м. MOVL
@(R0)+,@(R0)+
- Переведите каждую из инструкций п. 1 упр. 7.2 в машинный код.
- Перепишите программы п. 3, 5 или 6 из предыдущего набора упр. 7.1 так, чтобы максимально использовать режимы адресации с автоувеличением или автоуменьшением,
- Перепишите программы п. 3, 5 или 6 из предыдущего набора упр. 7.1 так, чтобы максимально использовать индексный режим адресации.
- Напишите программу, которая осуществляет ввод 35 чисел в порядке, соответствующем последовательному просмотру матрицы размером 5x7 по строкам. Напечатайте эти числа в том порядке, в котором бы они следовали при просмотре этой матрицы по столбцам.
- * Двумерный массив можно сканировать по строкам или по столбцам. Каким образом можно выполнить сканирование трёхмерного массива? Напишите программу, которая осуществляет ввод 60 чисел, формирует массив размера 3x4x5 и затем печатает эти 60 чисел в порядке, соответствующем всем возможным способам сканирования. (Сканирование в обратном направлении не считается новым способом.)
| < НАЗАД | ОГЛАВЛЕНИЕ | ВПЕРЁД > |