А. ДИКОВ, А. КАЛАШНИКОВ, А. КУЛАКОВ
TermOS
Операционная мини-система TermOS с автоматическим управлением накопителем на магнитной ленте разработана с целью максимального облегчения работы пользователей БК-0010(-01) с НМЛ (бытовым магнитофоном). Своё название система получила от «ТарЕ Recorder Machine OS», что буквально можно перевести как «магнитофонная операционная система».
Основным отличием TermOS от других известных программ автоматического управления НМЛ является то, что сама управляющая программа и каталоги кассет загружаются в дополнительное ОЗУ, использующее область адресов 140000 - 157777 (при подключении такого ОЗУ к БК-0010-01 ПЗУ с Бейсиком автоматически отключается), и остаются там резидентно, т.е. могут быть «испорчены» лишь преднамеренно выключением питания или занесением в эту область новой информации.
TermOS может работать либо с одним каталогом, либо с двумя одновременно, запоминая показания счётчиков лент при переходе от одной кассеты к другой. Благодаря этому для считывания нового файла нет нужды перематывать ленту в начало. А если учесть полностью автоматизированное управление магнитофоном (перемотку влево, вправо, завись и воспроизведение включает непосредственно БК), то становится правомерным сравнение БК с «большими» ЭВМ конца 60-х гг.
Выбор необходимых функций системы осуществляется через меню. Система меню является иерархической и многоуровневой. Её суть заключается в том, что в верхней строке экрана высвечивается главное меню, каждая функция которого может иметь своё меню (низшего уровня), помещающееся во второй строке. Если у выбранной функции меню низшего уровня нет, то во второй строке помещается объяснение действия выбранной функции. В меню низшего уровня может быть своё меню ещё более низкого уровня и т.д. Таким образом, пользователю нет необходимости запоминать все команды системы - они находятся на экране; остаётся лишь выбрать необходимое, передвигаясь по меню вправо - влево и «в глубину».
Основные функции системы:
- загрузка программ по адресу, указанному в оглавлении файла, либо по адресу, указанному пользователем;
- загрузка и запуск программ;
- подмотка ленты к указанному файлу;
- фиктивное чтение имён файлов;
- копирование группы файлов в указанной последовательности либо в полностью автоматическом режиме с использованием второго магнитофона (управляемого только по питанию), либо на одном магнитофоне с выдачей подсказок о смене кассет;
- распечатка файлов на экране или принтере в символьном виде;
- то же для указанного фрагмента ОЗУ;
- управление режимами печати принтера (включение и отключение подчёркивания, печати выделенным, черновым, уплотнённым шрифтом, шрифтом двойной ширины и высоты, печать графической информации с экрана и т.д.);
- переход от каталога одной кассеты к каталогу другой;
- удаление имён файлов из каталога (но не с МЛ);
- восстановление удалённых имён файлов в каталоге;
- запись обновлённого каталога на магнитную ленту;
- инициализация системы;
- выход в монитор, МСТД, Фокал (возможен выход с последующим дублированием всей появляющейся на экране информации на принтер и управлением принтером с клавиатуры либо из выполняемой программы).
При любых сбоях счётчика ленты (даже внесённых преднамеренно) управляющая программа замечает ошибку и производит программную коррекцию счётчика, не перематывая ленту в начало.
Если указанную программу считать с ленты не удалось, TermOS делает вторую попытку и, если она окажется неудачной, выдаёт об этом сообщение, а в каталоге делает отметку, подчёркивая дефектный файл.
Применённая система меню позволяет легко изменить конфигурацию системы - включить дополнительные функции, исключить ненужные. С этим может справиться пользователь, имеющий опыт работы с ассемблером и листинг программы TermOS.
Возможна зашивка программы TermOS в ПЗУ с адреса 120000, т.е. запуск ОС при включении машины, что делает систему ещё более удобной (это не исключит возможность работы с Фокал-программами).
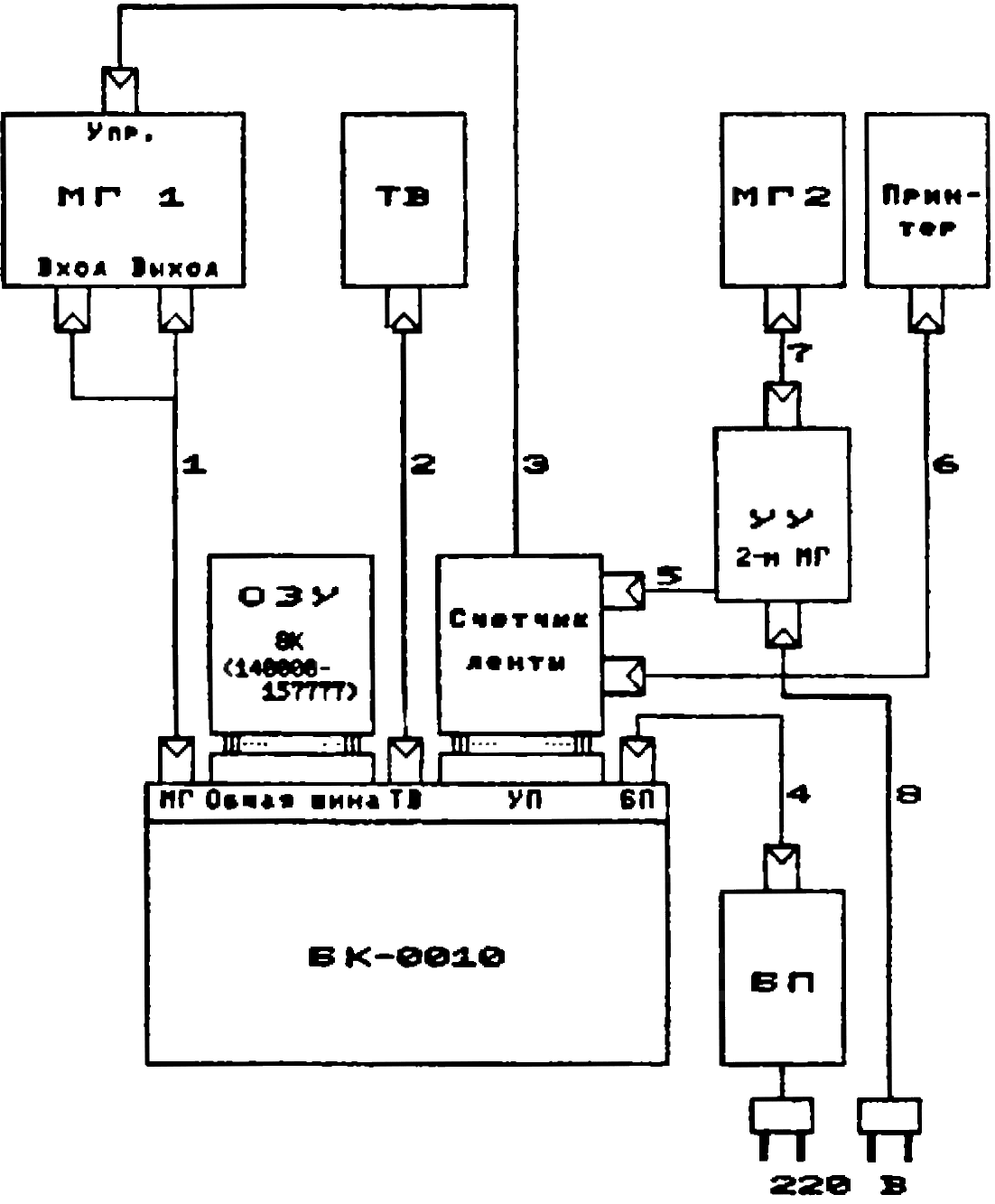
TermOS предназначена для работы с комплексом, включающим:
- устройство расширения ОЗУ;
- специальным образом доработанный магнитофон с электронно-логическим управлением, используемый в качестве НМЛ;
- устройство управлением вторым магнитофоном при копировании файлов.
Блок-схема комплекса приведена на рисунке.
Заинтересовавшиеся могут писать по адресу: 123497, Москва, ул. Рогова, 14, корп. 1, кв. 85, Кулакову Александру Тихоновичу.
(Продолжение следует.)
В следующих номерах журнала будет рассказано об устройстве расширения ОЗУ и доработке магнитофона.
Энергонезависимое ОЗУ
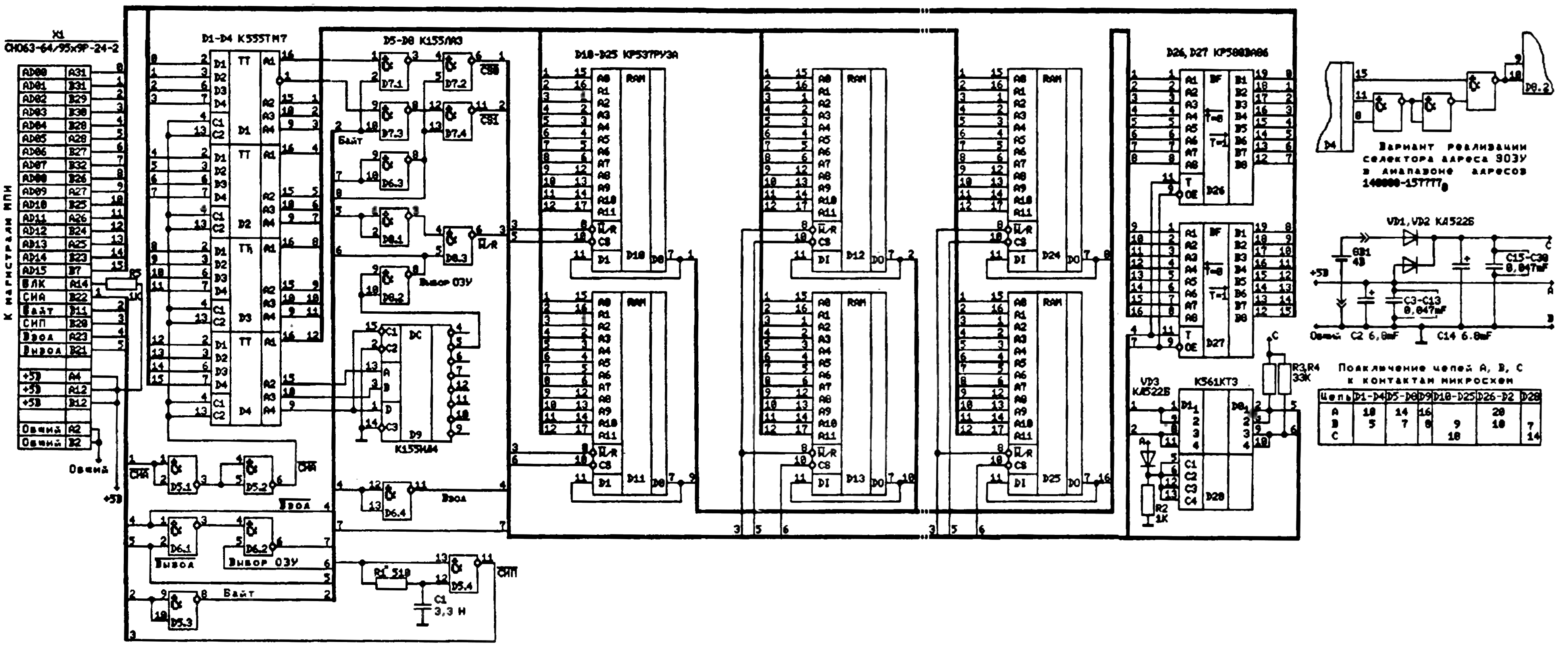
Энергонезависимое ОЗУ (ЭОЗУ) предназначено для расширения объёма ОЗУ пользователя компьютера БК-0010.01. Подключается к магистрали МПИ вместо блока МСТД, при этом БИС ПЗУ языка Бейсик автоматически блокируются.
ЭОЗУ выполнено на микросхемах статической памяти типа КР537РУЗА. Объём памяти - 8К байт, этого достаточно для размещения практически любой системной программы.
ЭОЗУ может работать в любом месте адресного пространства компьютера, но целесообразно размещать его с адреса 120000(8) или 140000(8).
Программы, помещённые в ЭОЗУ, можно подвергать изменению неограниченное число раз. Для сохранения информации при отключении или сбоях питания предусмотрен буферный источник питания.
Основные технические характеристики:
- напряжение батареи питания - 4 В;
- ток, потребляемый от источника 5В компьютера - 150 мА,
- ток, потребляемый от батареи в режиме хранения информации - 100 мкА.
Регистр адреса собран на микросхемах D1 - D4 (К5555ТМ7), их выходы образуют шину адреса ЭОЗУ. Адрес обращения к ОЗУ фиксируется в регистре сигналом СИА. Три старших разряда шины адреса использованы для адресации ЭОЗУ, они подведены к селектору адреса, выполненному на микросхеме D9 (К155ИД4). С помощью перемычек может быть выбрана любая область адресного пространства компьютера с интервалом 20000(8).
Шинные формирователи D26 - D27 (КР580ВА86) образуют шину данных. Направление передачи данных определяется сигналом ВВОД магистрали. Шина данных находится в активном состоянии только в момент непосредственной передачи данных (активен либо сигнал ВВОД, либо сигнал ВЫВОД).
Непосредственно ОЗУ выполнено на 16 микросхемах D10 - D25 (КР537РУЗА). На схеме условно показана только часть микросхем.
Сигнал СИП вырабатывается на выходе элемента D5.4 при активном сигнале ВВОД или ВЫВОД
Микросхемы D7, D8 вырабатывают сигнал записи-считывания W/R и сигналы выборки кристалла CS0, CS1 для старшего и младшего байтов ОЗУ при выполнении операций чтения-записи байта.
Ключ D28 (К561КТЗ) совместно с устройством подключения буферного источника питания GB1 к микросхемам памяти обеспечивают блокировку сигналов выборки кристаллов при сбоях и отключении питания компьютера; при этом микросхемы памяти и ключ оказываются под напряжением GB1, достаточным для сохранения информации.
Изготовление ЭОЗУ может быть выполнено любым доступным пользователю способом. При исправных деталях и правильном монтаже ЭОЗУ не требует наладки.
А. БАРСУКОВ
Просмотрщик памяти
Хороший отладчик кодовых программ - полезнейшая вещь: он позволяет просмотреть и изменить содержимое ОЗУ, произвести пошаговое выполнение программы, установить контрольные точки и т.п. Подобных программ для БК-0010 существует немало. Стоит ли добавлять к ним ещё одну, вдобавок имеющую довольно скромные возможности? Решайте сами. Предлагаемая ниже программа может только просматривать и изменять содержимое ОЗУ, а также искать нужное слово или байт, но зато занимает 1600(8) байтов (OTL9, например, занимает 11000(8)). К тому же её можно разместить в той части ОЗУ, которая используется для хранения служебной строки экрана, и, таким образом, не ущемить прикладную программу ни на байт.
При работе программы для каждого слова памяти на экране индицируются его адрес, значение, разбивка на байты в числовом и символьном видах. Предусмотрены следующие режимы работы (в скобках - включающие их клавиши и команды):
- следующее слово (ВНИЗ);
- предыдущее слово (ВВЕРХ);
- установить адрес (А <адрес> ВВОД);
- изменить слово (ВВОД <значение> ВВОД);
- изменить байт (ВС <значение> ВВОД);
- задать модель для поиска (М <модель> ВВОД);
- искать слово (I);
- искать байт (Q);
- очистить экран (СБР);
- окончить работу (КТ).
Если программа вас заинтересовала - введите её в БК, дайте команду RUN. Экран очистится. В служебной строке разместится сама программа, а на экране появится содержимое нулевого слова. Проверьте правильность исполнения описанных команд (для проверки изменения содержимого ОЗУ используйте свободную область с адреса 20000). После окончания проверки нажмите клавишу КТ и вернитесь в транслятор Бейсика командой S120170. Убедитесь, что вы не повредили важных областей памяти. Для этого повторно запустите программу и снова вернитесь в Бейсик.
Теперь осталось записать на МЛ кодовый вариант программы. Для этого удалите строку 100 и запустите программу командой RUN; в служебной строке сформируется кодовый вариант программы. Запишите его командой
BSAVE "<имя>",&O40000,&O41600
Программа является абсолютно перемещаемой. Её можно загрузить в любое место памяти с адреса 1000 до адреса 40000. Желаемый адрес загрузки можно задать в команде BLOAD или указать его при создании программы, изменив значение в строке 10 (и в команде BSAVE соответственно). Загрузка программы в ОЗУ пользователя несколько увеличивает скорость вывода информации на экран.
Несколько замечаний об использовании программы в экранном ОЗУ. Скорость вывода можно увеличить, периодически очищая экран. Внимательно вводите числовые значения. Нажатие любой клавиши, выводящей информацию в служебную строку, может повредить программу. Перед каждой новой загрузкой программы не забывайте устанавливать значение регистра рулонного сдвига двукратным нажатием клавиш АР2+СБР.
При вводе чисел исправления не допускаются. В случае ошибки ввода нажмите клавишу СТОП и повторите ввод. Попытки изменить ПЗУ блокируются.
1 ? CHR$(140),CHR$(140) 10 A%=&O40000 20 D%=&O1600 30 N%=A% 40 B%=A%+D% 50 READ S% 60 POKE N%,S% 70 N%=N%+2 80 IF N%<B% THEN 50 90 DEF USR=A% 100 A=USR(A) 110 END 120 DATA &O10767,&O1376,&O5037,&O220,&O12706,&O1000 130 DATA &O12700,&O233,&O105737,&O40,&O1401,&O104016 140 DATA &O105737,&O56,&O1402,&O5300,&O104016,&O5003 150 DATA &O52737,&O100,&O177660,&O10700,&O62700,&O1274 160 DATA &O10037,&O20,&O12700,&O14,&O104016,&O10700 170 DATA &O62700,&O20,&O10037,4,&O403,&O12700 180 DATA &O14,&O104016,&O4767,&O536,&O32737,&O100 190 DATA &O177716,&O1374,&O32737,&O200,&O177660,&O1414 200 DATA &O13767,&O177662,&O1232,&O42767,&O177640,&O1224 210 DATA &O12700,7,&O104016,&O16700,&O1212,&O402 220 DATA &O16700,&O1204,&O120027,3,&O1013,&O12716 230 DATA &O100442,&O11637,4,&O42737,&O100,&O177660 240 DATA &O12700,&O236,&O104016,&O207,&O120027,&O33 250 DATA &O1004,&O4767,&O1020,&O5723,&O723,&O120027 260 DATA &O32,&O1006,&O5703,&O1716,&O5743,&O4767 270 DATA &O736,&O712,&D120027,&O12,&O1006,&O112700 280 DATA &O76,&O104016,4,&O10513,&O764,&O120027 290 DATA &O23,&O1012,&O4167,&O254,&O140742,&O152312 300 DATA &O72,&O110513,&O12701,1,&O74103,&O747 310 DATA &O120027,&O55,&O1004,&O12701,1,&O74103 320 DATA &O655,&O120027,&O14,&O1002,&O104016,&O650 330 DATA &O120027,&O101,&O1010,&O4167,&O172,&O142341 340 DATA &O142722,&O20323,&O72,&O10503,&O632,&O120027 350 DATA &O115,&O1011,&O4167,&O144,&O147755,&O142704 360 DATA &O154314,&O72,&O10567,&O724,&O616,&O120027 370 DATA &O111,&O1017,&O4167,&O124,&O147760,&O151711 380 DATA &O27313,&O40,&O42767,&O100000,&O124,&O42767 390 DATA &O100000,&O120,&O4767,&O102,&O427,&O120027 400 DATA &O121,&O1261,&O4167,&O60,&O147760,&O151711 410 DATA &O20313,&O140702,&O152312,&O27301,&O40,&O52767 420 DATA &O100000,&O52,&O52767,&O100000,&O46,&O5203 430 DATA &O4767,&O26,&O42703,1,&O167,&O177306 440 DATA &O5002,&O104020,4,&O201,&O5002,&O104020 450 DATA &O201,&O10305,&O20327,&O177500,&O103005,&O5723 460 DATA &O21367,&O540,&O1371,&O207,&O10503,&O12700 470 DATA 7,&O104016,&O104016,&O104016,&O207,&O4437 480 DATA &O110346,&O12700,&O232,&O104016,&O5000,&O10305 490 DATA &O4767,&O154,&O12700,&O40,&O104016,&O104016 500 DATA &O12700,&O10,&O11305,&O4767,&O132,&O12700 510 DATA &O40,&O104016,&O104016,&O12700,&O20,&O11305 520 DATA &O4767,&O126,&O12700,&O56,&O104016,&O12700 530 DATA &O24,&O11305,&O305,&O4767,&O104,&O12700 540 DATA &O40,&O104016,&O104016,&O104026,&O12701,&O31 550 DATA &O104024,&O11300,&O4767,&O146,&O300,&O4767 560 DATA &O140,&O104026,&O12701,&O35,&O104024,&O12700 570 DATA &O231,&O104016,&O12700,&O232,&O104016,&O4437 580 DATA &O110362,&O207,&O12767,6,&O40,&O12767 590 DATA 1,&O36,&O406,&O12767,3,&O22 600 DATA &O12767,2,&O20,&O4437,&O110346,&O104026 610 DATA &O10001,&O104024,&O12703,3,&O12702,2 620 DATA &O5000,&O6305,&O6100,&O77203,&O52700,&O60 630 DATA &O104016,&O12702,3,&O77312r&O4437,&O110362 640 DATA &O207,&O10046,&O42700,&O177400,&O20027,&O40 650 DATA &O2406,&O20027,&O200,&O101405,&O20027,&O240 660 DATA &O103002,&O12700,&O40,&O104016,&O12600,&O207 670 DATA &O26727,&O152,&O40000,&O2407,&O104026,&O5702 680 DATA &O1004,&O12700,&O24,&O104016,&O207,&O12700 690 DATA &O32,&O104016,&O207,&O26727,&O114,&O40000 700 DATA &O2423,&O104026,&O20227,&O26,&O2417,&O5002 710 DATA &O104024,&O12700,&O232,&O104016,&O12700,&O23 720 DATA &O104016,&O12702,&O26,&O104024,&O12700,&O232 730 DATA &O104016,&O207,&O12700,&O33,&O104016,&O207 740 DATA &O42737,&O100,&O177660,&O4737,&O100472,&O52737 750 DATA &O100,&O177660,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 760 DATA 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 770 DATA 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
А. ИНГОРЬ
Удобный аналог команды MERGE
Для объединения текстов программ, написанных на языке Бейсик-БК, служит заявленная, но не реализованная в вильнюсской версии языка 1987 г. команда MERGE. Вместе с тем имеется ряд программ в машинных кодах, восполняющих этот недостаток, однако для их работы требуется запись текстов объединяемых программ в крайне неэкономном формате команды SAVE, а подавляющее большинство пользователей БК предпочитают ей команду CSAVE, позволяющую хранить на дефицитной магнитной ленте программы в наиболее компактном виде.
В связи с этим практическая значимость имеющихся на сегодня программ-аналогов команды MERGE невысока и требуется поиск новых подходов к решению этой проблемы.
Предлагаемая программа CMERGE позволяет объединять в ОЗУ БК программы, записанные в формате команды СSAVE. Программа перемещаема и может загружаться с любого адреса; например, можно воспользоваться приводимой ниже процедурой и загрузить её в область буфера команды SAVE, что является наиболее удобным с точки зрения экономии адресного пространства в Бейсик-системе БК. Загруженную программу можно записать на МЛ командой BSAVE и пользоваться ею по мере надобности, вызывая командой BLOAD "CMERGE",&O37400,R. Всякий раз при этом программа CMERGE будет запрашивать имя добавляемой программы из пяти символов и по команде ВВОД объединять по логике команды MERGE нужный текст с текстом программы в ОЗУ БК.
Для многократного вызова программы CMERGE удобно определить её как функцию пользователя командой DEF USR=&O37400 и вызывать на исполнение командой А=USR(A) с параметром любого типа. Перед вызовом программы CMERGE следует произвести процедуру «сборки мусора», поскольку в результате редактирования или применения программы CMERGE строки текста программы в памяти БК могут расположиться не вплотную друг к другу, а при объединении нескольких больших фрагментов это может привести к потере текста. Сжать текст в памяти БК и убрать «мусор» можно командой RUN, не обращая внимания на ошибки её исполнения.
Для объяснения принципа программы CMERGE рассмотрим размещение текстов программ в памяти БК. Текст с ленты записывается сразу же вслед за текстом в памяти БК, причём на место сшивки указывает содержимое слова &O2002, а длина загруженного текста хранится в слове &O266. Строки программ в обоих текстах хранятся без номеров и не всегда в порядке их возрастания. Списки номеров и адресов соответствующих строк хранятся отдельно: для исходного текста список идёт с адреса, записанного в &О2026, в сторону уменьшения, а для подгружаемого текста список идёт сразу же вслед за текстом. Адреса строк в списке соответствуют загрузке строк с адреса &О3052, причём второе слово от конца загруженного текста указывает на конец списка. Для каждой строки текста в списке выделены три слова, важны два из них: слово со старшим адресом содержит номер, а следующее за ним - адрес строки.
Зная эту структуру данных, можно сформировать новый список строк, имитируя работу оператора MERGE и взяв в качестве буфера экранную область памяти БК. По завершении формирования списка он копируется программой CMERGE из буфера на место списка строк исходной программы.
Процедура загрузки программы CMERGE:
10 DATA &O12701,&O320,&O12721,&O3,...... ............................................................. ............................................................. 100 FOR I%=0 TO 74 110 READ A% 120 POKE &O37400+I%*2,A% 130 NEXT I% 140 DEF USR=&O37400
Текст программы:
|
12701 |
320 |
12721 |
3 |
13721 |
|
2002 |
5021 |
12703 |
100724 |
4737 |
|
100460 |
12702 |
5005 |
12700 |
334 |
|
4737 |
137670 |
4737 |
100566 |
105700 |
|
1064 |
13705 |
264 |
63705 |
266 |
|
10502 |
14500 |
160005 |
12700 |
2024 |
|
13704 |
2002 |
162704 |
3052 |
10537 |
|
2002 |
34242 |
13701 |
2026 |
5741 |
|
12703 |
52000 |
20205 |
3423 |
20110 |
|
3410 |
21211 |
2406 |
1413 |
11143 |
|
14143 |
14143 |
5741 |
764 |
11243 |
|
14243 |
60413 |
14243 |
5742 |
756 |
|
162701 |
6 |
767 |
20110 |
3360 |
|
12701 |
52000 |
13702 |
2026 |
14142 |
|
20103 |
3375 |
10210 |
137 |
120234 |
А. ГАРМАШОВ
Ю. ЗАЛЬЦМАН, В. МИХАЙЛОВ
БК-0010 - речь и слух: возможности и реальность
Начнём с конца: синтезатор речи с неограниченным словарём для микро-ЭВМ БК-0010 прекрасно работает с 1989 г. Он может выводить в виде речевой информации (на русском языке) произвольный текст, выдаваемый микро-ЭВМ на экран, причём форма представления текста в памяти ЭВМ - самая обыкновенная, стандартный код КОИ-8, и слова - по обычным правилам грамматики, а не особая, «фонетическая», запись, как во многих известных системах, в том числе зарубежных. Каким переделкам для этого подверглась сама ЭВМ? Никаким. Какие внешние дополнительные устройства требуются для воспроизведения речи? Никакие. Сколько места в памяти занимает синтезатор? 8К байт.
Зачем понадобилось это вступление? Дело в том, что, когда мы начинали работу по созданию синтезатора речи для БК 0010, не было ни одного (!) человека, включая и нас самих, который после изложения требований к синтезатору сказал бы, что это возможно. Потому лучше сразу уверить читателя в том, что все дальнейшие рассуждения не являются голой теорией, а блестяще подтвердились на практике (чем не могут похвастаться многие и многие разработки в этой области).
Итак, с чего всё началось? Казахскому обществу слепых (КОСу) потребовалось оборудование, с которым мог бы работать слепой пользователь: набирать на клавиатуре текст, редактировать его и затем распечатывать как специальным шрифтом для слепых (шрифт Брайля), так и обычным шрифтом. Что же тут такого, скажете вы? Существуют специальные пишущие машинки для слепых (действительно, существуют) и даже специальные ЭВМ (да, но только не у нас). Проблема состояла в том, чтобы слепой мог подготовить текст, а не просто его распечатать. Такое оборудование, существующее за рубежом и разрабатывающееся у нас, базируется в основном на преобразовании текста в динамическую (т.е. постоянно меняющуюся, «бегущую» по тексту) строку символов Брайля - матриц из 6 или 8 точек (оборудование класса «Версобрайль»). Определённое сочетание рельефных точек позволяет обозначить все русские и латинские буквы, цифры и даже нотные знаки и спецсимволы.
Однако шрифт Брайля слепой читает обычно двумя руками, и исправлять ошибки (работать на клавиатуре) ему просто нечем. Нужны невероятные память и воображение, чтобы сопоставить, не видя текста, символы на бегущей строке и те изменения, которые нужно внести в текст на клавиатуре (к слову сказать, установка типа «Версобраиль» тоже была нами сконструирована и входила в комплект оборудования, но не о ней речь).
Вот тут и возникла мысль о синтезаторе речи. Если слепой сможет слышать, что выдаёт компьютер на экран, то внести в текст изменения ему будет гораздо легче - руки свободны! Да и пульт для работы тоже брайлевский - всего восемь клавиш.
До начала работы мы, авторы разработки, не знали о синтезе речи почти ничего. Приходилось, конечно, слышать в научно-популярных телепередачах фразы, произнесённые необычным, «машинным» голосом, и видеть за спиной ведущего машинные залы, в которых стояли электронные «чудища», этот голос производящие. Но сейчас эпоха персоналок, электронные «динозавры» вымирают... Какая ЭВМ сможет нам помочь в реализации идеи? Выбор определялся крайне скромным финансированием разработки - компьютеры класса IBM PC отпали поэтому сразу. В то время (да и сейчас мало что изменилось) единственной сколько-нибудь стоящей дешёвой машиной был БК-0010. Дешёвой - понятно, а почему стоящей? Да потому, что это был единственный 16-разрядный компьютер среди бытовых, все остальные - 8-разрядные. Если кто-то считает, что это не так важно, то с ним больше говорить не о чём. Ведь что было задумано? Задача на пределе возможностей средней или даже большой ЭВМ (так нам тогда представлялось). Итак, мы начали работу, не надеясь, впрочем, на полный успех.
Известно немало методов синтеза речи: спектрально-полосовой, гармонический, корреляционный, формантный, КЛП-синтез и др. Все они нам не подходили - как по причине требующихся большой памяти и быстродействия, так и потому, что их использование почти обязательно требует наличия специальных внешних устройств - цифроаналоговых преобразователей (ЦАП), формантных фильтров, специализированных сопроцессоров и т.п. Мы же были крайне ограничены в средствах (и во времени), а кроме того, хотели сделать программу, которая смогла бы работать на любом БК -0010 без всяких проблем.
Оставался так называемый фонемный цифровой синтез, т.е. «сборка» речи из отдельных звуков (фонем), как из кубиков. Прочтя несколько высокоинтеллектуальных теоретических работ, мы испугались - оказывается, в любом языке фонем гораздо больше, чем букв в алфавите! Фонем больше сотни! Да ещё «стыковать» их друг с другом нужно по особым правилам, количество которых достигает несколько сотен... Куда тут с 16К байтами ОЗУ! Но после жарких споров, за которые авторы монографий и докторских диссертаций, услышь они их, придушили бы нас на месте - так рьяно опровергали мы то, на что они потратили годы труда, - мы всё же пришли к выводу, что дело не безнадёжно.
Во-первых, русский язык почти фонетический - пишем почти так, как говорим (не то что англичане!). Во-вторых, на БК уже были опыты прямой записи речи в память (как на цифровом магнитофоне), и довольно успешные. В-третьих, мы были уверены, что наши возможности как программистов ограничены только возможностями самого БК-0010 - мы знали его идеально. Вот это, да ещё присущая любому дилетанту уверенность в том, что профессионалы всегда сгущают краски, и дало нам преимущество.
Начали мы с того, что сделали простейший «фонетический редактор» - он позволял «загрузить» в память БК (в экранное ОЗУ) речевую информацию с микрофона (продолжительностью 10-12 с), затем «вырезать» из речи отдельные звуки и «склеить» из них нужное слово. О чудный миг, когда машина произнесла первую фразу, не записанную с микрофона, а «склеенную» из отдельных фонем: «Маша ела кашу»! Мы думали, что задача решена! Но самое сложное оказалось впереди...
Поскольку мы смело отвергли опыт синтеза речи, накопленный «мировой общественностью» (так как опыт этот однозначно говорил, что создать на БК синтезатор речи невозможно), нам пришлось накапливать свой. Мы очень скоро убедились, что буква звучит по-разному в зависимости от того, где она стоит - в начале, середине, конце слова или отдельно. Кроме того, соседние буквы, как «выяснилось» (всё это давно и хорошо известно), очень сильно влияют на её звучание! К этому времени мы имели уже очень неплохой фонетический редактор, позволяющий создать настоящий «алфавит фонем» и экспериментировать с ним, синтезируя слова и фразы просто по коду КОИ-8 символов.
Начался каторжный труд создания «словаря». Мы по-прежнему надеялись подобрать такое звучание фонем, соответствующих буквам, которое будет компромиссным и удовлетворит все фонетические тонкости при числе фонем, равном 30 (твёрдый и мягкий знаки не в счёт, а буква «ё» на компьютерах отсутствует). Мы отлично понимали, что с большим числом фонем БК просто не справится! А ведь нужно было ещё оставить в памяти место для других программ...
Цель эта была достигнута - мы подобрали такие фонемы, которые звучали удовлетворительно, в каком бы окружении ни стояла буква.
Правда, решить задачу «в лоб» не удалось: оказалось недостаточным просто «вырезать» из речи тот или иной звук или специально его «наговорить» (представьте себе, кстати, эту картину, двое программистов сидят у компьютера и орут по очереди в микрофон что-то несусветное, мычат, шипят, поют, а потом лихорадочно манипулируют с клавиатурой и слушают с блаженными улыбками, как компьютер с диким, ни на что не похожим акцентом произносит - в основном популярные скороговорки типа «На дворе трава, на траве дрова»). Литература рекомендует прибегнуть для создания словаря фонем к услугам профессионального диктора; мы обошлись без него, так как убедились, что качество речи при наших скромных возможностях (частота дискретизации порядка 8 кГц) очень мало зависит от наличия или отсутствия косноязычия. Кроме того, какой диктор выдержит три месяца фонетических «упражнений»? Но словарь фонем упорно не давался! Стоило выбрать фонемы, отлично звучащие в составе одного слова, как другое становилось совершенно неразборчивым... Особенно мучили согласные - никак не удавалось наговорить звуки так, чтобы «б» отличалось от «п», а «ж» от «ш». Вместо «в» почему-то слышалось «з», а «о» и «а» звучали, совершенно произвольно «меняясь ролями» в зависимости от окружения, в котором они пребывали... Дальнейший успех определило решающее «открытие»: очень многое зависит от длительности звуков.
Как только в редактор были внесены соответствующие изменения, и мы смогли менять длительность и частоту воспроизведения звуков, дело пошло на лад. Мы даже стали получать одни звуки из других - глухие из звонких и наоборот. Но так называемые взрывные - «б», «п», «т» - не давались по-прежнему. И тут пришло второе «открытие» (а может быть, и действительно открытие, без кавычек, так как в литературе ничего подобного не нашлось). Оказывается, предшествующая звуку короткая пауза (мы назвали её «лидером») придаёт необходимое «взрывное» звучание. В итоге словарь фонем, удовлетворительно звучащих в любых комбинациях без всяких модификаций и «связок», был создан.
Тут, видимо, следует объяснить, как мы вводили в БК речь. Простейшим путём - через подключённый к компьютеру магнитофон (а позже - специально созданный усилитель с полосовыми фильтрами и интеграторами) и обычный микрофон (позже - высококачественный электретный). На входе «МГ» БК, как известно, включён компаратор напряжения, преобразующий любой звуковой сигнал в двухуровневый логический. Оставалось с определённой частотой считывать этот сигнал со входа и побитно заносить его в ОЗУ (это называется дискретизацией сигнала).
Из известной теоремы Котельникова следует, что для восстановления дискретизированного сигнала без потерь частота дискретизации должна по крайней мере в два раза превышать максимальную частоту обрабатываемого сигнала. Частотный спектр речи очень широк, и, «по Котельникову», следовало выбрать частоту опроса входного сигнала как можно большей. Но словарь фонем не должен был занимать много места, и мы использовали частоту дискретизации около 8 кГц, что обеспечивало восстановление спектральных составляющих с частотой не более 4 кГц.
Тут обнаружилась ещё одна проблема. Пока информация пишется по одному биту в 16-разрядное слово БК-0010, всё идёт нормально - выбранная частота соблюдается, так как в цикле работают однотипные операторы программы. Но затем нужно занести это слово в ОЗУ, модифицировать адрес памяти и начать «набивать» битами новое слово. А при этом образуется пауза, вроде бы ничтожная, около 35 микросекунд, но основательно портящая дело - ведь происходит сбой частоты дискретизации. При воспроизведении звуков при переходе от одного машинного слова к другому возникает такая же пауза. Складываясь, они основательно искажают звучание. Пришлось прибегнуть к специальным ухищрениям, чтобы скомпенсировать паузу при записи звуков - пауза при воспроизведении в одиночестве вреда не причиняла.
Кстати, чем выше частота дискретизации, тем заметнее её сбои при переходе к следующему машинному слову. Это, кроме ограниченной памяти, также заставило выбрать частоту около 8 кГц - при дальнейшем её повышении качество речи начинало падать.
Для воспроизведения мы вначале просто подключали к БК магнитофон в режиме «запись», но скоро убедились, что его частотная характеристика с сильным подъёмом в области высоких частот, мягко говоря, не идеальна для этой цели. Тогда был использован обычный усилитель низкой частоты с регулировкой тембра (от проигрывателя), и звучание синтезированной речи сразу настолько улучшилось, что мы опять подумали - задача решена.
Когда был создан словарь фонем, и мы убедились, что он вполне работоспособен (проверяли так: один набирал на клавиатуре фразу или слово, обычно редкое и неожиданное, а другой на слух старался понять его), во весь рост встал вопрос: как будет выглядеть сам синтезатор речи? Ведь в тексте есть множество «мелких пакостей» типа цифр, ударений, латинских букв, знаков препинания... Русский язык всё же не вполне фонетичен; например, редко говорят «чего», но - «чево», произносят «што» вместо «что» и т.д. И та самая пресловутая буква «ё» - давно исключённая из печатного текста, она очень сильно сказывается на произношении! Попробуйте-ка сказать «ёлка» с «е» вместо «ё»!
Как решаются эти проблемы «по-настоящему», мы знали - либо создаётся свод правил (например, ударений; но каково создать такие правила для русского языка?!), либо словарь, в котором есть все нужные варианты произношения, либо то и другое - свод правил и словарь исключений. Ясно, что на БК это было невозможно. Мы стали экспериментировать и убедились, что речь без ударений почти не теряет в разборчивости; что «ё» в 99 % случаев можно заменить на «о», которая в контексте воспринимается почти нормально... Очевидно, живые люди часто не соблюдают правил произношения, и все давно привыкли к «нелитературным» вариантам типа «чего» и даже не замечаем их.
Кстати, ещё раньше мы убедились, что хотя почти невозможно распознать на слух отдельные звуки нашего словаря фонем, но, слитые в слова, они звучат как ни в чём не бывало! Психологи называют этот феномен «целостностью восприятия» (в данном случае звукового образа). Так, рассматривая в лупу газетную репродукцию, мы видим лишь точки, но стоит посмотреть издали - и картина предстаёт целой.
Итак, мы отказались от ударений и изменения звучания букв в разных словах, пожертвовав правильностью речи синтезатора в пользу его существования, но оставались ещё вещи, которые никак нельзя обойти. Мы начали с твёрдого знака. Открытие, что пауза (почти равная по длительности звуку) прекрасно его заменяет, нас приятно удивило. После этого мы уже смело заменили мягкий знак более короткой паузой, констатировав, что он - всего лишь анахронизм, вроде буквы «ять», благополучно почившей 70 лет назад. Но про знаки препинания и цифры мы, увы, так сказать не могли. Была ещё одна сложность: нужно было обеспечить возможность выделения отдельных букв текста на слух, но, как уже говорилось выше, отдельные фонемы словаря не различались - требовался звуковой образ, слово.
Мы вспомнили, как решается такая задача у радиотелефонистов в почти аналогичной ситуации - при плохой разборчивости речи. Слова называют при этом по буквам, используя обычно имена, начинающиеся с той буквы, которую необходимо обозначить, например: А - Алексей, Б - Борис, В - Василий и т.д. Взяв у знакомого радиолюбителя-коротковолновика список «ключевых слов», мы экспериментально его опробовали и заменили некоторые общепринятые слова на другие, которые наш синтезатор более чётко проговаривал.
Совсем просто решилась проблема цифр - они всегда называются полностью, когда их коды встречаются в тексте, вот и всё: «один», «два», «три» и т.д. От произнесения многоразрядных чисел типа «сто двадцать три» вместо «один, два, три» мы отказались сразу - сложно, да и не всегда нужно; кто, например, произносит номер телефона, как «шестьсот девяносто одна тысяча семьсот девяносто семь»?! Со знаками препинания и спецсимволами мы тоже справились некоторые должны произноситься всегда полностью, например «плюс», а некоторые - заменяться паузами, например запятая.
Но как быть, если нужно исправить именно эти знаки в тексте? И родилась ещё одна ключевая идея - два режима синтеза, слитный и посимвольный, выбираемые пользователем. В слитном слова произносятся так, как мы их читаем (в основном по правилу «один символ - один звук», исключение цифры); вместо знаков препинания - паузы. В другом же режиме называются все символы кода КОИ-8, включая даже коды управления курсором («вверх», «влево-вверх», «сброс экрана» и т.д.). Латинские символы синтезатор всегда должен называть, как буквы английского алфавита - «эй», «би», «си», «ди» и т.д. Обычно это два звука, которые довольно легко понять на слух. От синтеза английской речи у нас хватило ума отказаться - английский язык очень далёк от фонетического, и БК он не по зубам[1].
Таким образом, общее представление о структуре синтезатора сложилось, но проблемы оставались. Всё это должно было работать в реальном масштабе времени, да ещё занимать мало места в памяти - вечная проблема! Как тут быть с множеством слов - имён и названий, которые должен выдавать синтезатор вместо кодов КОИ-8? Нашёлся отличный выход - синтезатор использует сам себя: все длинные слова и фразы типа «сброс экрана», «точка с запятой» написаны тоже в коде КОИ-8, и синтезатор произносит их по звукам, используя свой же словарь фонем!
Итак, на входе синтезатора - символ в коде КОИ-8. По таблице «код-адрес» программа находит адрес строки, в которой (тоже в коде КОИ-8) записано, что должен сказать синтезатор. При этом учитывается режим (слитной речи или посимвольный) и происходит обращение к той или иной таблице фраз. Допустим, режим посимвольный, на входе - код 341 (заглавная русская буква А; синтезатор не различает заглавные и строчные буквы). Обратившись к ячейке 341 первой таблицы, программа находит там адрес, а по этому адресу - два разных указания: одно - просто «А», второе - слово «Алексей». Определив, что режим - посимвольный, синтезатор начинает выборку по буквам второго слова, сопоставляя каждой букве фонему из словаря, причём фонемы сразу переводятся в импульсы, поступающие на выход компьютера. Звучит речь. (Заметим, что сам словарь фонем - весьма сложная структура, состоящая из таблиц, где каждой фонеме сопоставлен не только её адрес в памяти, но и длительность звучания, и частота звука - они у всех звуков разные.)
А если нужно синтезировать слова не русской речи, а другого языка? Что же, русская фонетика довольно богата, и с её помощью можно эмулировать, видимо, любой язык. Казахский реализован, делались опыты с итальянским, французским, испанским (про английский и говорить нечего - попробовали первым!) - вполне успешно: люди, не знакомые с данным языком (целостность звукового образа отсутствует!), довольно легко понимали и повторяли произнесённые синтезатором слова и фразы. Конечно, слова иностранных языков приходится записывать подходящими русскими буквами (фонетическая запись текста, принятая во многих зарубежных системах).
Надо сказать, что к синтезированной речи приходится привыкать, чтобы понимание её стало лёгким и безошибочным. Большинству людей для этого требуется не более часа, после чего навык остаётся на всю жизнь. Судя по монографиям, не только наш синтезатор требует тренировки для лёгкого восприятия синтезированной речи. Считается, что синтезатор хорош, если после такой тренировки правильно воспринимается около 80% слов. Смеем заверить, что наш даёт гораздо лучший процент восприятия, хотя специально мы его не тестировали.
Вот как будто и всё. Синтезатор был создан, тема сдана, слепые довольно легко научились работать с компьютером и понимать его речь. Увы, судьба этой разработки оказалась типичной для нашей страны - о ней никто не знает. Приспособление, могущее облегчить и скрасить жизнь тысячам инвалидов по зрению, помочь в обучении слепых детей, да и мало ли в чём ещё, существует в единственном экземпляре. Правда, сама программа гораздо более распространена - её тиражируют (имя файла - ГОВОРУН, вы ещё с ним не знакомы?) и покупают. Пользователи БК приходят в восторг, а те из них, кто представляет, что это за труд - создать синтезатор речи, - восторгаются энтузиазмом программистов, сделавших это «за так». Но теперь вы всю историю знаете и можете не умиляться нашему энтузиазму и бескорыстию - синтезатор ГОВОРУН создан «в порядке служебного задания». Восхититесь лучше великолепными бюрократическими навыками чиновников, которые, имея такую разработку в своём полном распоряжении, не торопятся её внедрить в той области, для которой она предназначена. Что ж, над ними не каплет. И тратятся ежегодно большие средства на разработку компьютерных систем для слепых - на основе более дорогих и сложных машин, часто импортных. Впрочем, и это понятно - всем есть-пить надо... Такой вот немного грустный финал.
А что же аванс, данный в заглавии? Насчёт слуха? Неужели можно на БК и это?! Ведь задача анализа слитной речи не решена ещё нигде! Даже на мощных и дорогих машинах имеются только частные случаи решений - ограниченный словарь понимаемых машиной слов, ограниченный круг общающихся с ней операторов... Да, это так. И «аванс» пока не более чем трюк, рассчитанный на привлечение внимания читателя к статье. И всё-таки... Что же скрывать - мы думаем и над этой проблемой, и есть уже кое-какие идеи. Но нет пока организации или предприятия, которым это было бы нужно, а делать такие вещи «на энтузиазме» - пусть, кто хочет, верит, что это возможно! Ведь надо работать, т.е. заниматься делом, за которое платят зарплату.
Ну а в принципе - если вы не верите, что можно создать на БК программу, понимающую речь, то, значит, рассказанная история создания синтезатора речи вас ничему не научила.
Литература
- Косарев Ю.А. Естественная форма диалога с ЭВМ. Л.: Машиностроение, 1989.
- Обжелян Н.К., Трунин-Донской В.И. Машины, которые говорят и слушают. Кишинев: Штиинца, 1987.
- Михайлов В.Г., 3латоустова Л.В. Измерение параметров речи. М.: Радио и связь, 1987.
- Горелов И.Н Разговор с компьютером: Психолингвистический аспект проблемы. М.: Наука, 1987.
[1] Если же кто-нибудь, не знающий этого, докажет обратное, мы с удовольствием опубликуем рассказ о том, как это происходило.— Примеч. ред.